Chapter 5 Foundations for inference
Data and data sets are not objective; they are creations of human design. We give numbers their voice, draw inferences from them, and define their meaning through our interpretations. —Katie Crawford
Chapter by Matthew Crump
So far we have been talking about describing data and looking possible relationships between things we measure. We began by talking about the problem of having too many numbers. So, we discussed how we could summarize big piles of numbers with descriptive statistics, and by looking at the data with graphs. We also looked at the idea of relationships between things. If one thing causes another thing, then if we measure how one thing goes up and down, we should find that other thing goes up and down, or does something at least systematically following the first thing. At the end of the chapter on correlation, we showed how correlations, which imply a relationship between two things, are very difficult to interpret. Why? because an observed correlation can be caused by a hidden third variable, or simply be a spurious findings “caused” by random chance. In the last chapter, we talked about sampling from distributions, and we saw how samples can be different because of random error introduced by the sampling process.
Now we begin our journey into inferential statistics. The tools we use to make inferences about where our data came from, and more importantly make inferences about what causes what.
In this chapter we provide some foundational ideas. We will stay mostly at a conceptual level, and use lots of simulations like we did in the last chapters. In the remaining chapters we formalize the intuitions built here to explain how some common inferential statistics work.
5.1 Brief review of Experiments
In chapter one we talked a little bit about research methods and experiments. Experiments are a structured way of collecting data that can permit inferences about causality. If we wanted to know whether something like watching cats on YouTube increases happiness we would need an experiment. We already found out that just finding a bunch of people and measuring number of hours watching cats, and level of happiness, and correlating the two will not permit inferences about causation. For one, the causal flow could be reversed. Maybe being happy causes people to watch more cat videos. We need an experiment.
An experiment has two parts. A manipulation and a measurement. The manipulation is under the control of the experimenter. Manipulations are also called independent variables. For example, we could manipulate how many cat videos people will watch, 1 hour versus 2 hours of cat videos. The measurement is the data that is collected. We could measure how happy people are after watching cat videos on a scale from 1 to 100. Measurements are also called dependent variables. So, in a basic experiment like the one above, we take measurements of happiness from people in one of two experimental conditions defined by the independent variable. Let’s say we ran 50 subjects. 25 subjects would be randomly assigned to watch 1 hour of cat videos, and the other 25 subjects would be randomly assigned to watch 2 hours of cat videos. We would measure happiness for each subject at the end of the videos. Then we could look at the data. What would we want to look at? Well, if watching cat videos cause change in happiness, then we would expect the measures of happiness for people watching 1 hour of cat videos to be different from the measures of happiness for people watching 2 hours of cat videos. If watching cat videos does not change happiness, then we would expect no differences in measures of happiness between conditions. Causal forces cause change, and the experiment is set up to detect the change.
Now we can state one overarching question, how do we know if the data changed between conditions? If we can be confident that there was a change between conditions, we can infer that our manipulation caused a changed in the measurement. If we cannot be confident there was a change, then we cannot infer that our manipulation caused a change in the measurement. We need to build some change detection tools so we can know a change when we find one.
“Hold on, if we are just looking for a change, wouldn’t that be easy to see by looking at the numbers and seeing if they are different, what’s so hard about that?” Good question. Now we must take a detour. The short answer is that there will always be change in the data (remember variance).
5.2 The data came from a distribution
In the last chapter we discussed samples and distributions, and the idea that you can take samples from distributions. So, from now on when you see a bunch of numbers, you should wonder, “where did these numbers come from?” What caused some kinds of numbers to happen more than other kinds of numbers. The answer to this question requires us to again veer off into the abstract world of distributions. A distribution a place where numbers can come from. The distribution sets the constraints. It determines what numbers are likely to occur, and what numbers are not likely to occur. Distributions are abstract ideas. But, they can be made concrete, and we can draw them with pictures that you have seen already, called histograms.
The next bit might seem slightly repetitive from the previous chapter. We again look at sampling numbers from a uniform distribution. We show that individual samples can look quite different from each other. Much of the beginning part of this chapter will already be familiar to you, but we take the concepts in a slightly different direction. The direction is how to make inferences about the role of chance in your experiment.
5.2.1 Uniform distribution
A uniform distribution is completely flat, it looks like this:
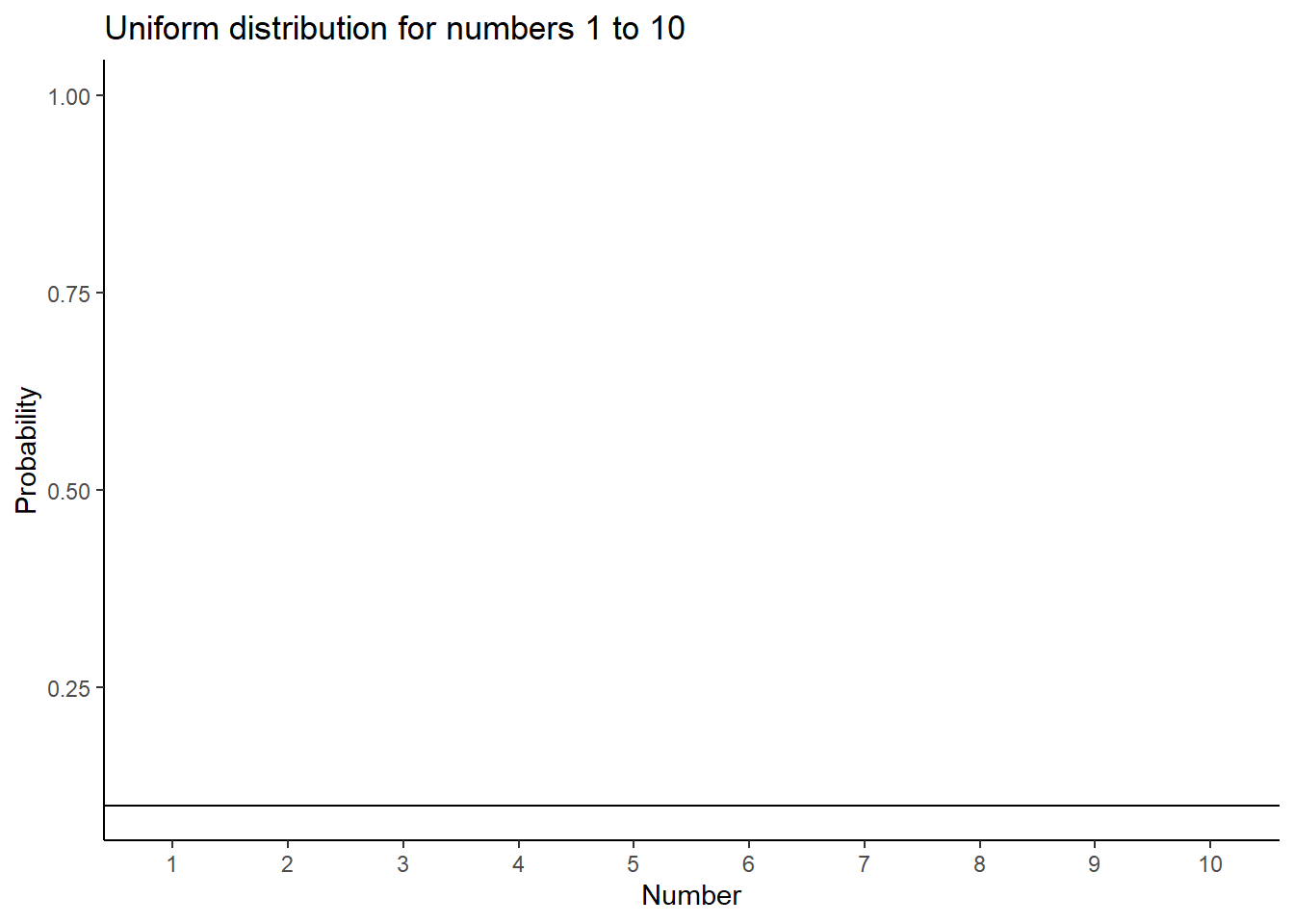
Figure 5.1: Uniform distribution showing that the numbers from 1 to 10 have an equal probability of being sampled
OK, so that doesn’t look like much. What is going on here? The y-axis is labelled probability, and it goes from 0 to 1. The x-axis is labelled Number, and it goes from one to 10. There is a horizontal line drawn straight through. This line tells you the probability of each number from 1 to 10. Notice the line is flat. This means all of the numbers have the same probability of occurring. More specifically, there are 10 numbers from 1 to 10 (1,2,3,4,5,6,7,8,9,10), and they all have an equal chance of occurring. 1/10 = .1, which is the probability indicated by the horizontal line.
“So what?” Imagine that this uniform distribution is a number generating machine. It spits out numbers, but it spits out each number with the probability indicated by the line. If this distribution was going to start spitting out numbers, it would spit out 10% 1s, 10% 2s, 10% 3s, and so on, up to 10% 10s. Wanna see what that would look like? Let’s make it spit out 100 numbers
| 8 | 6 | 2 | 2 | 4 | 8 | 7 | 9 | 9 | 4 |
| 4 | 9 | 4 | 7 | 3 | 9 | 1 | 2 | 1 | 4 |
| 5 | 1 | 2 | 4 | 4 | 10 | 10 | 8 | 6 | 2 |
| 1 | 8 | 1 | 2 | 7 | 8 | 8 | 4 | 2 | 10 |
| 3 | 4 | 10 | 1 | 1 | 3 | 5 | 9 | 8 | 6 |
| 10 | 10 | 4 | 7 | 6 | 6 | 2 | 7 | 2 | 3 |
| 1 | 4 | 2 | 7 | 9 | 9 | 7 | 3 | 2 | 5 |
| 7 | 9 | 2 | 7 | 1 | 6 | 6 | 2 | 8 | 2 |
| 6 | 4 | 7 | 5 | 5 | 8 | 6 | 7 | 5 | 2 |
| 5 | 5 | 5 | 9 | 7 | 10 | 6 | 10 | 1 | 4 |
We used the uniform distribution to generate these numbers. Officially, we call this sampling from a distribution. Sampling is what you do at a grocery store when there is free food. You can keep taking more. However, if you take all of the samples, then what you have is called the population. We’ll talk more about samples and populations as we go along.
Because we used the uniform distribution to create numbers, we already know where our numbers came from. However, we can still pretend for the moment that someone showed up at your door, showed you these numbers, and then you wondered where they came from. Can you tell just by looking at these numbers that they came from a uniform distribution? What would need to look at? Perhaps you would want to know if all of the numbers occur with roughly equal frequency, after all they should have right? That is, if each number had the same chance of occurring, we should see that each number occurs roughly the same number of times.
We already know what a histogram is, so we can put our numbers into a histogram and see what the counts look like. If all of the numbers occur with equal frequency, then each number should occur 10 times, because we sampled a total of 100 numbers. The histogram looks like this:
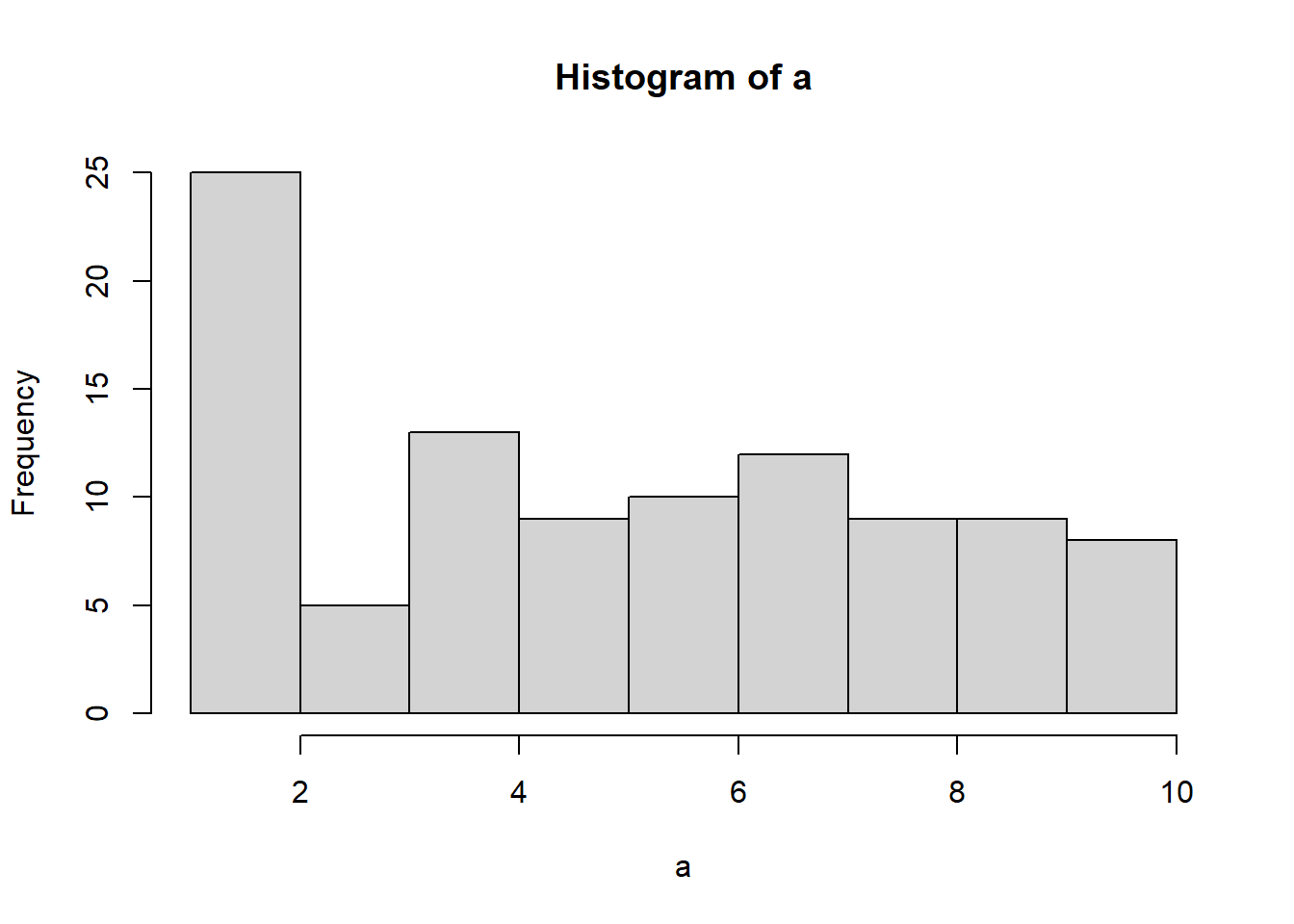
Figure 5.2: Histogram of a sampl of 100 numbers from the uniform distribution containing the integers from 1 to 10
Uh oh, as you can see, not all of the number occurred 10 times each. All of the bars are not the same height. This shows that randomly sampling numbers from this distribution does not guarantee that our numbers will be exactly like the distribution they came from. We can call this sampling error, or sampling variability.
5.2.2 Not all samples are the same, they are usually quite different
Let’s take a look at sampling error more closely. We will sample 20 numbers from the uniform. Here we should expect that each number between 1 and 10 occurs two times each. Let’s take 20 sample and make a histogram. And then, let’s do that 10 times. So we will be looking at 10 histograms, each showing us what the 10 different samples of twenty numbers looks like:
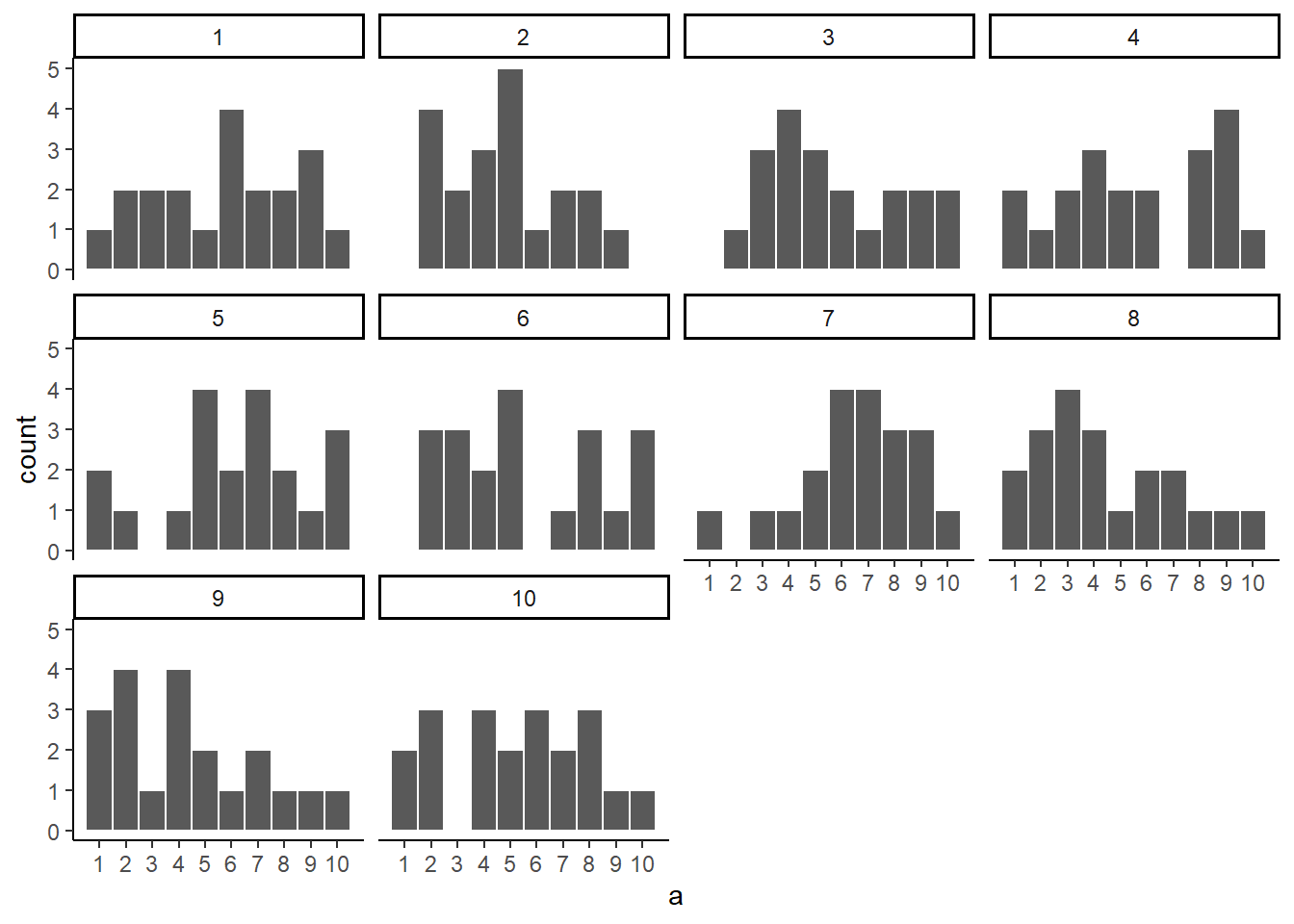
Figure 5.3: Histograms for 10 different samples from the uniform distribution. They all look quite different. The differences between the samples are due to sampling error
You might notice right away that none of the histograms are the same. Even though we are randomly taking 20 numbers from the very same uniform distribution, each sample of 20 numbers comes out different. This is sampling variability, or sampling error.
Here is movie version. You are watching a new histogram for each sample of 20 observations. The horizontal line shows the shape of the uniform distribution. It crosses the y-axis at 2, because we expect that each number (from 1 to 10) should occur about 2 times each in a sample of 20. However, as you can see, this does not happen. Instead, each sample bounces around quite a bit, due to random chance.
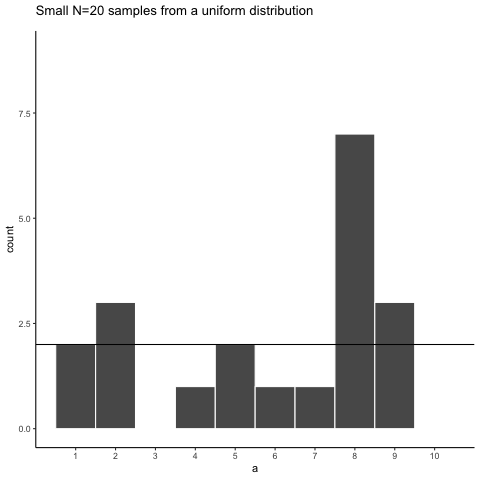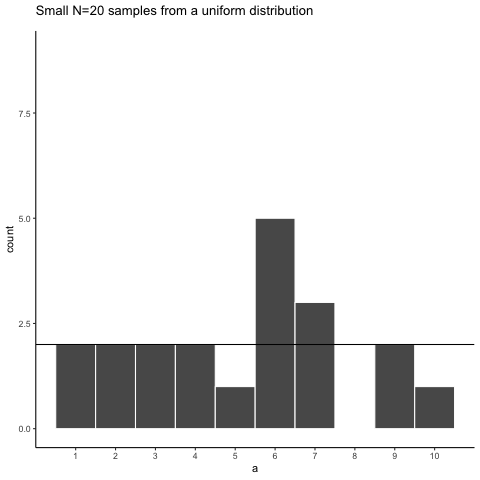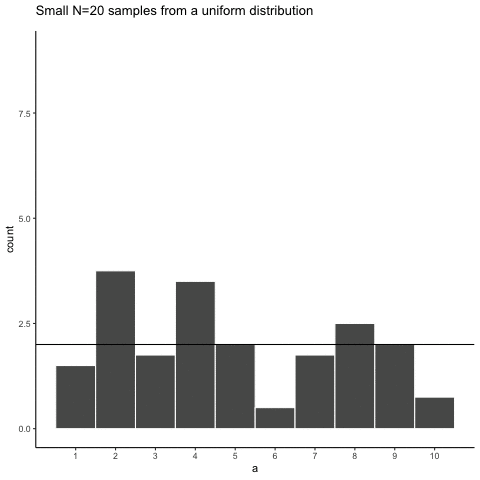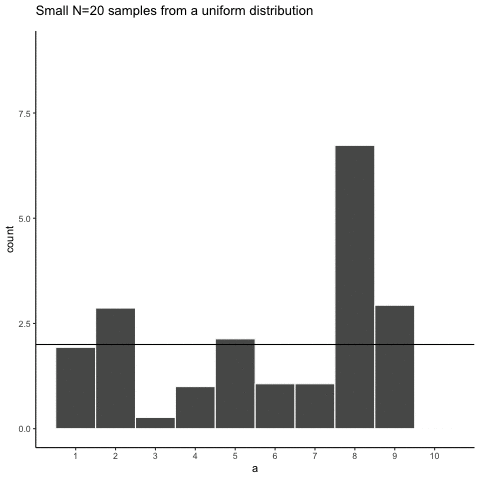
Figure 5.4: Animation of histograms for different samples of 20 from Uniform distribution (numbers 1 to 10). The black lines shows the expected number of times each number from 1 to 10 should occur. The fact that each number does not occur 2 times each illustrates the error associated with sampling
Looking at the above histograms shows us that figuring out where our numbers came from can be difficult. In the real world, our measurements are samples. We usually only have the luxury of getting one sample of measurements, rather than repeating our own measurements 10 times or more. If you look at the histograms, you will see that some of them look like they could have come from the uniform distribution: most of the bars are near two, and they all fall kind of on a flat line. But, if you happen to look at a different sample, you might see something that is very bumpy, with some numbers happening way more than others. This could suggest to you that those numbers did not come from a uniform distribution (they’re just too bumpy). But let me remind you, all of these samples came from a uniform distribution, this is what samples from that distribution look like. This is what chance does to samples, it makes the individual data points noisy.
5.2.3 Large samples are more like the distribution they came from
Let’s refresh the question. Which of these two samples do you think came from a uniform distribution?
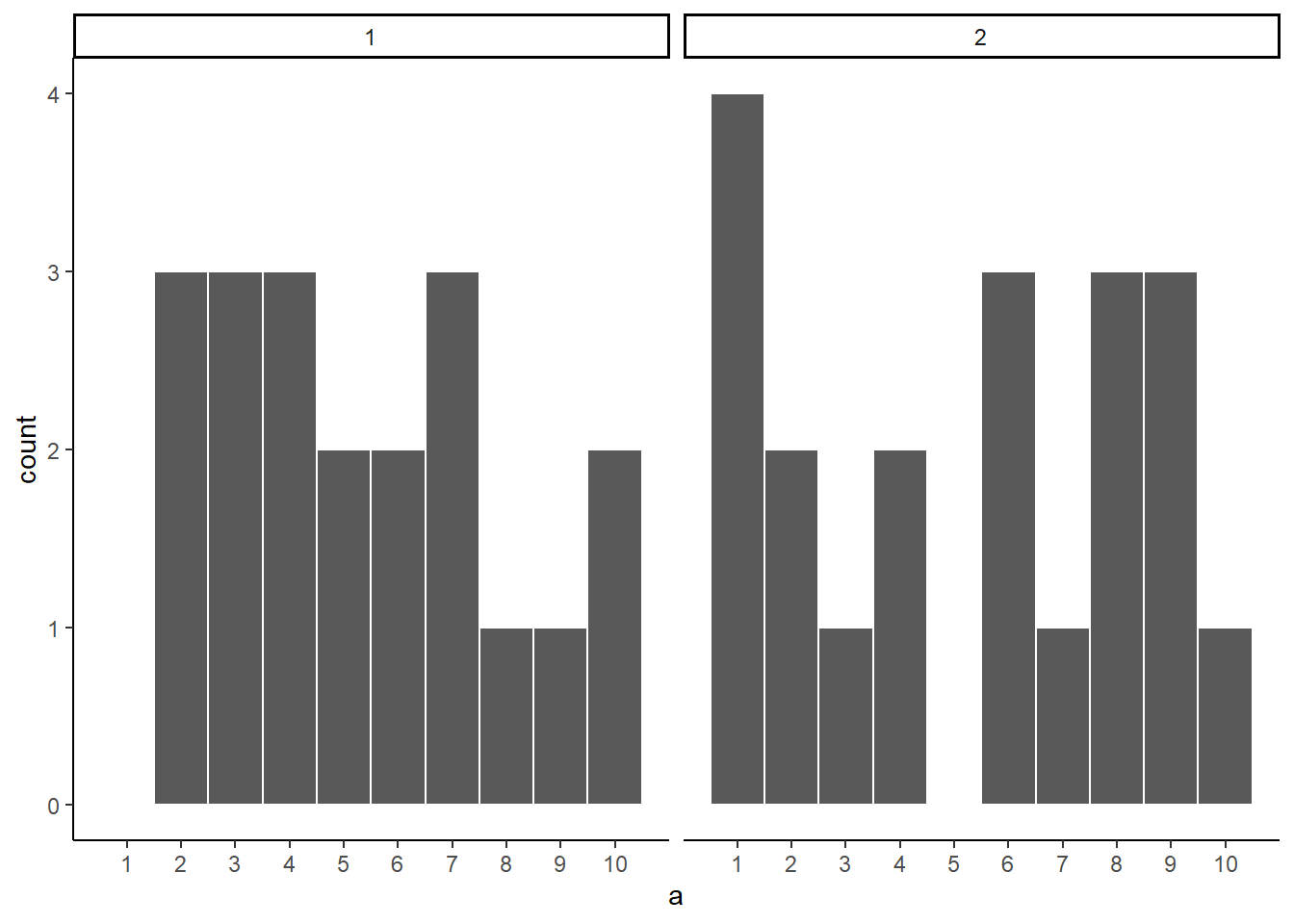
Figure 5.5: Which of these two samples came from a Uniformat distribution?
The answer is that they both did. But, neither of them look like they did.
Can we improve things, and make it easier to see if a sample came from a uniform distribution? Yes, we can. All we need to do is increase the sample-size. We will often use the letter n to refer to sample-size. N is the number of observations in the sample.
So let’s increase the number of observations in each sample from 20 to 100. We will again create 10 samples (each with 100 observations), and make histograms for each of them. All of these samples will be drawn from the very same uniform distribution. This, means we should expect each number from 1 to 10 to occur about 10 times in each sample. Here are the histograms:
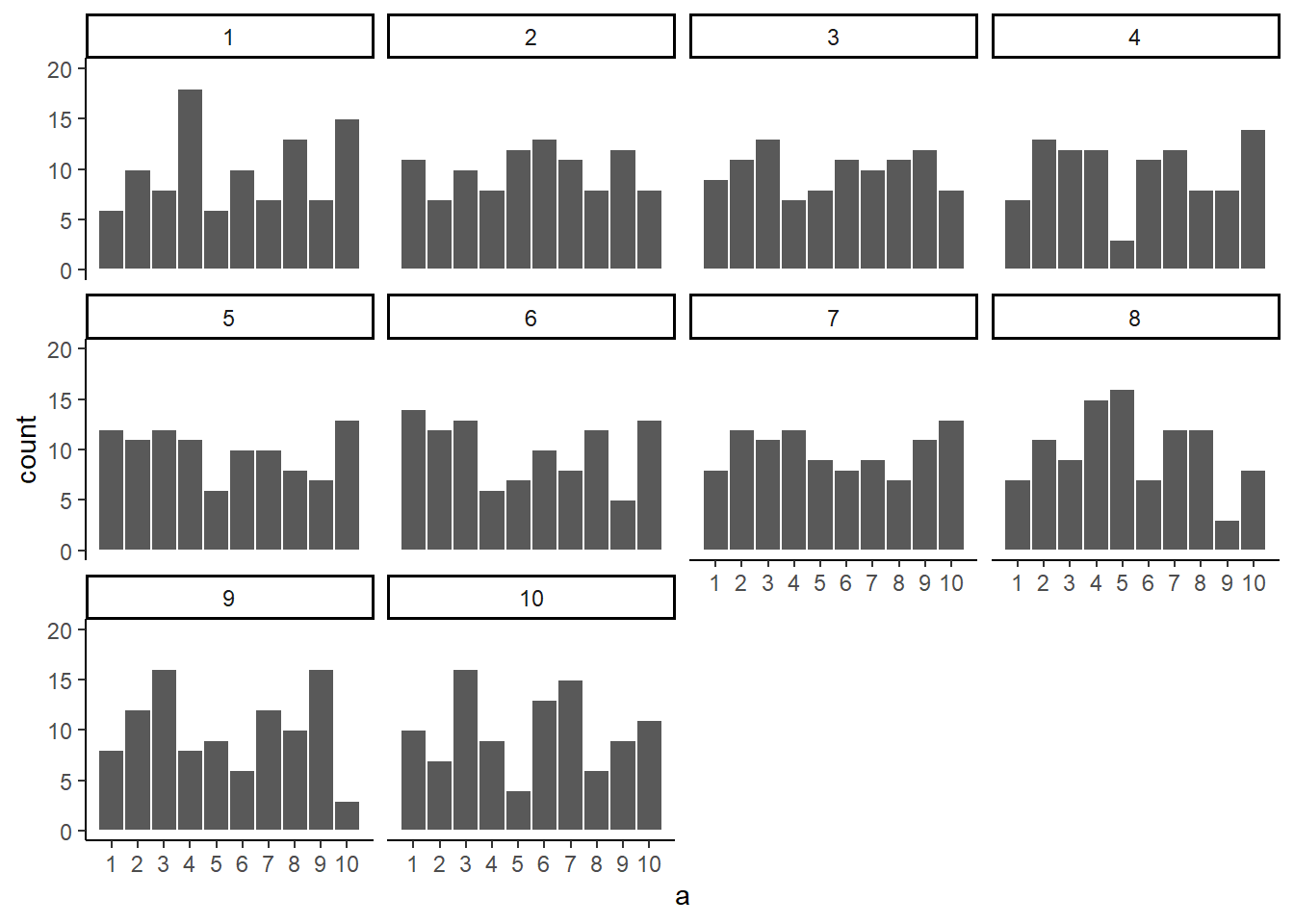
Figure 5.6: Histograms for different samples from a uniform distribution. Sample-size = 100 for each sample.
Again, most of these histograms don’t look very flat, and all of the bars seem to be going up or down, and they are not exactly at 10 each. So, we are still dealing with sampling error. It’s a pain. It’s always there.
Let’s bump it up to 1000 observations per sample. Now we should expect every number to appear about 100 times each. What happens?
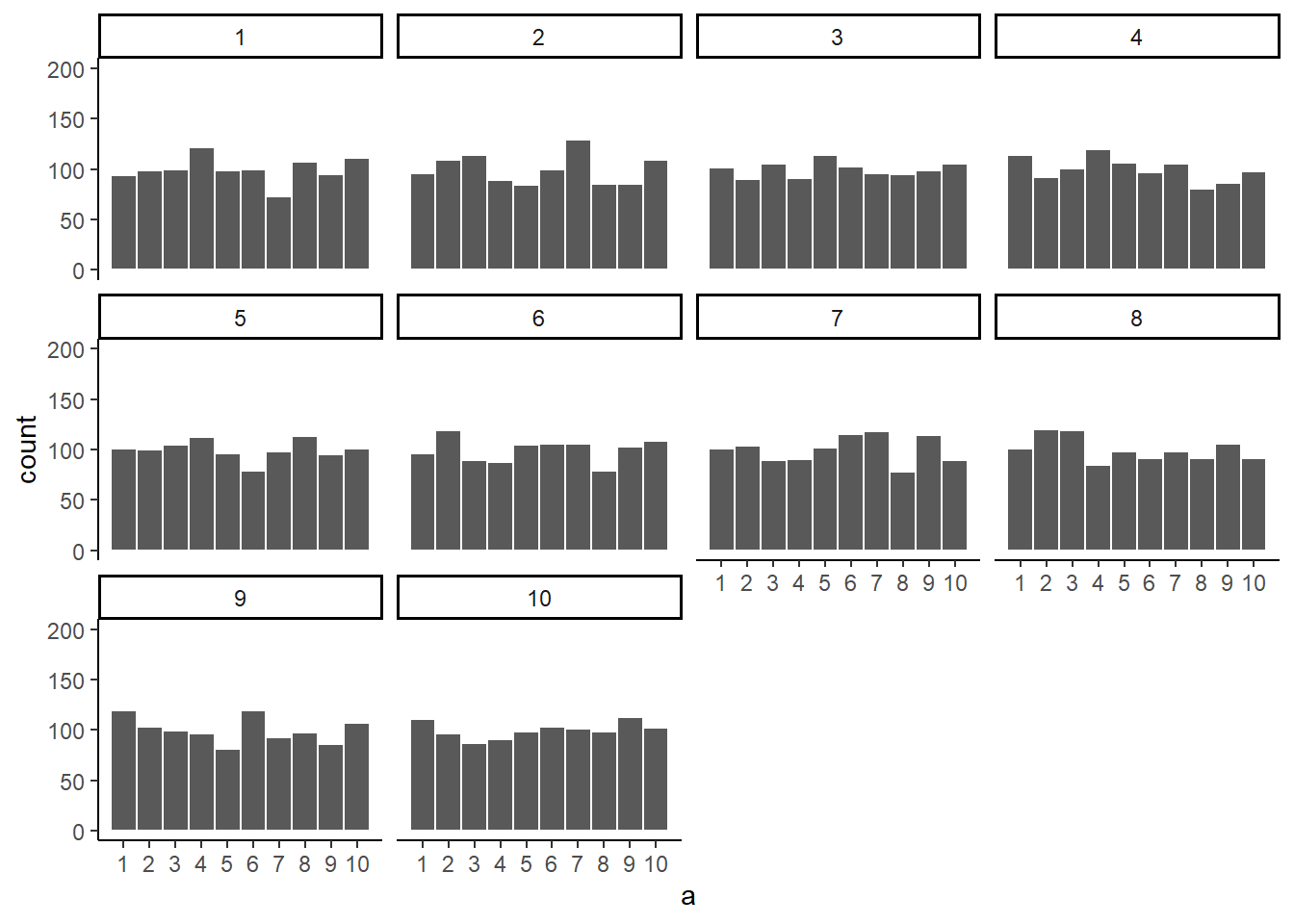
Figure 5.7: Histograms for different samples from a uniform distribution. Sample-size = 1000 for each sample.
Each of these histograms are starting to flatten out. The bars are still not perfectly at 100, because there is still sampling error (there always will be). But, if you found a histogram that looked flat and knew that the sample contained many observations, you might be more confident that those numbers came from a uniform distribution.
Just for fun let’s make the samples really big. Say 100,000 observations per sample. Here, we should expect that each number occurs about 10,000 times each. What happens?
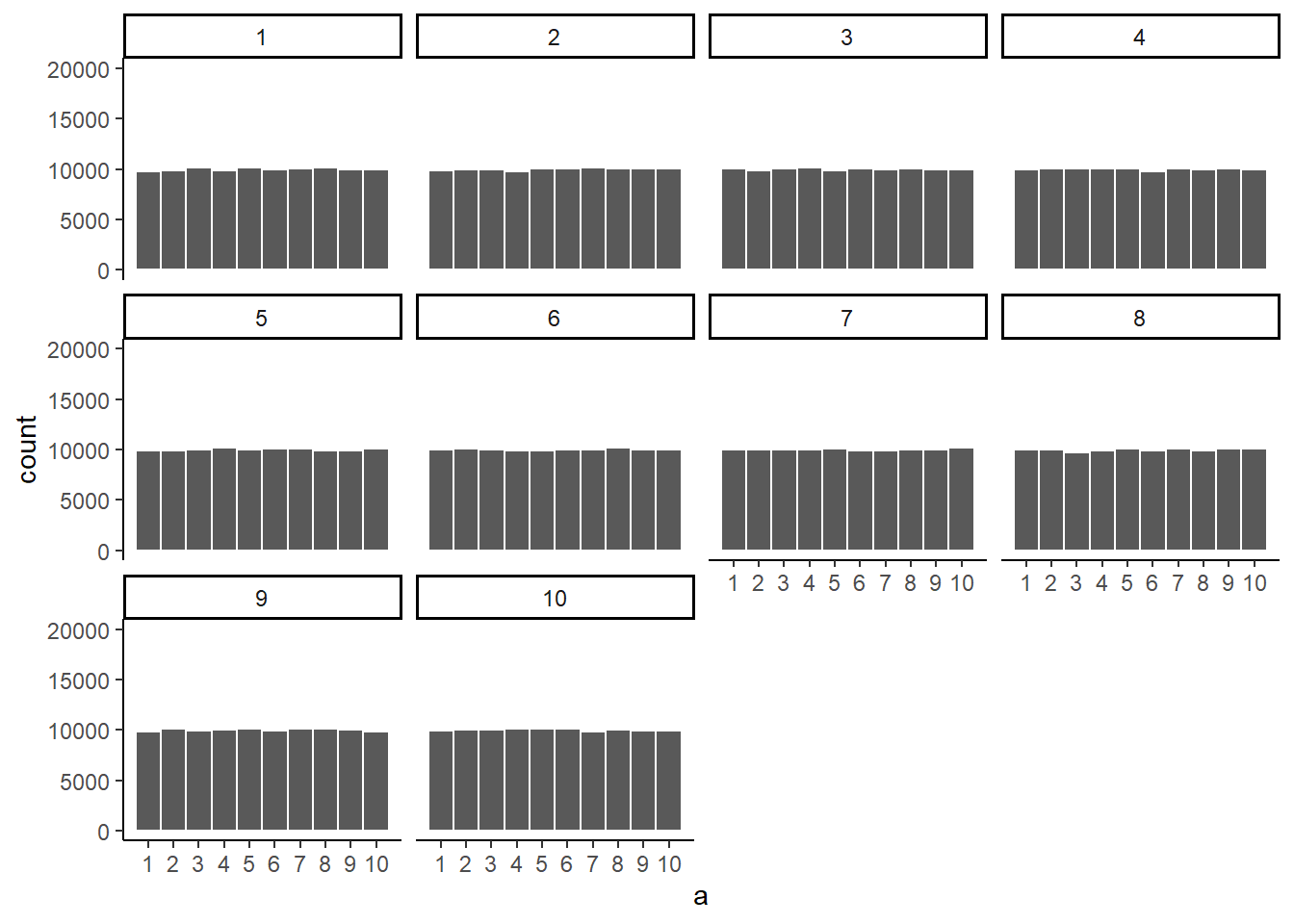
Figure 5.8: Histograms for different samples from a uniform distribution. Sample-size = 100,000 for each sample.
Now we see that all of our samples start to look the same. They all have 100,000 observations, and this gives chance enough opportunity to equally distribute the numbers, roughly making sure that they all occur very close to the same amount of times. As you can see, the bars are all very close to 10,000, where they should be if the sample came from a uniform distribution.
Pro tip: The pattern behind a sample will tend to stabilize as sample-size increases. Small samples will have all sorts of patterns because of sampling error (chance).
Before getting back to experiments, let’s ask two more questions. First, which of these two samples do you think came from a uniform distribution? I will tell you that each of these samples had 20 observations each.
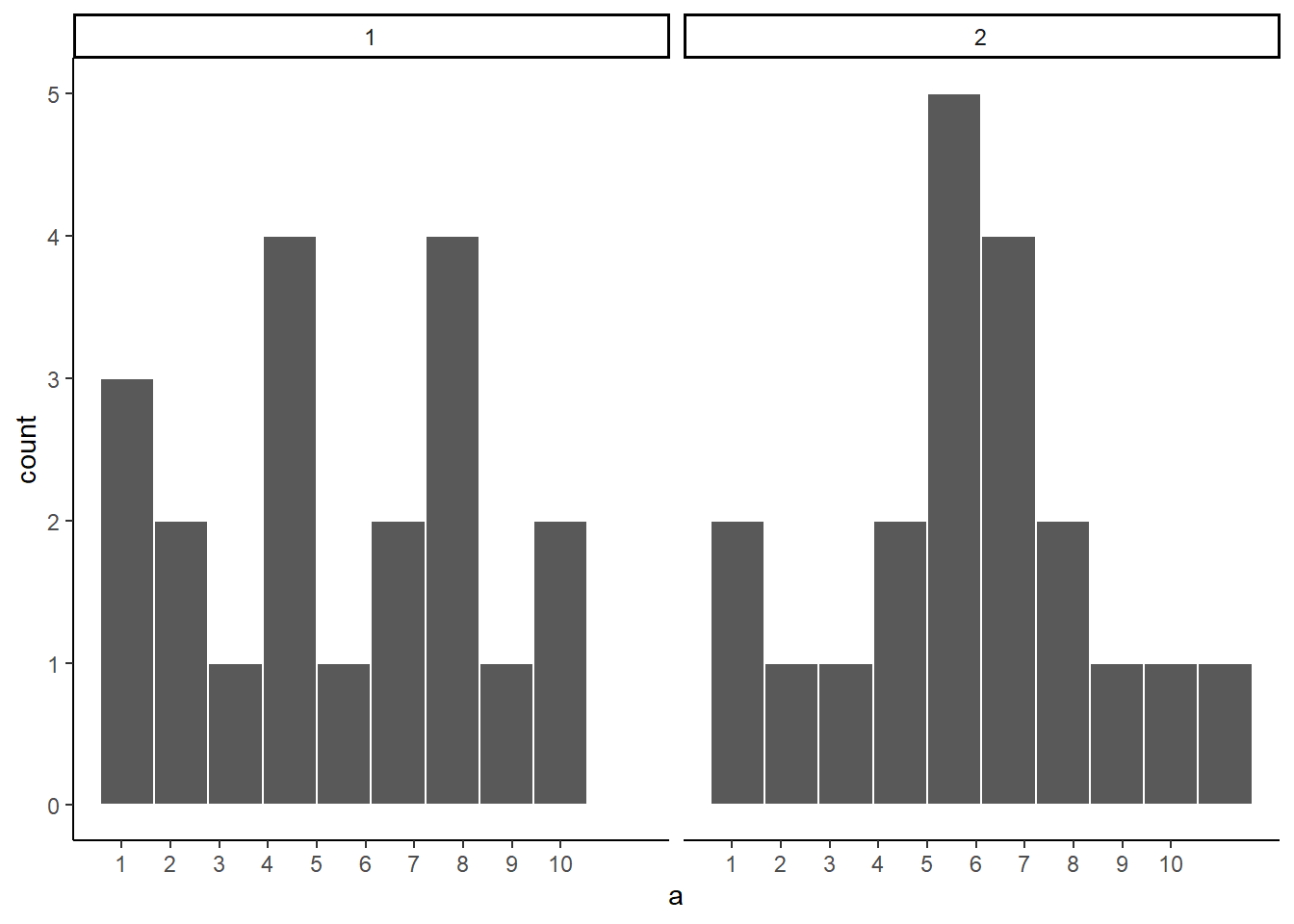
Figure 5.9: Which of these samples came from a uniform distribution?
If you are not confident in the answer, this is because sampling error (randomness) is fuzzing with the histograms.
Here is the very same question, only this time we will take 1,000 observations for each sample. Which one do you think came from a uniform distribution, which one did not?
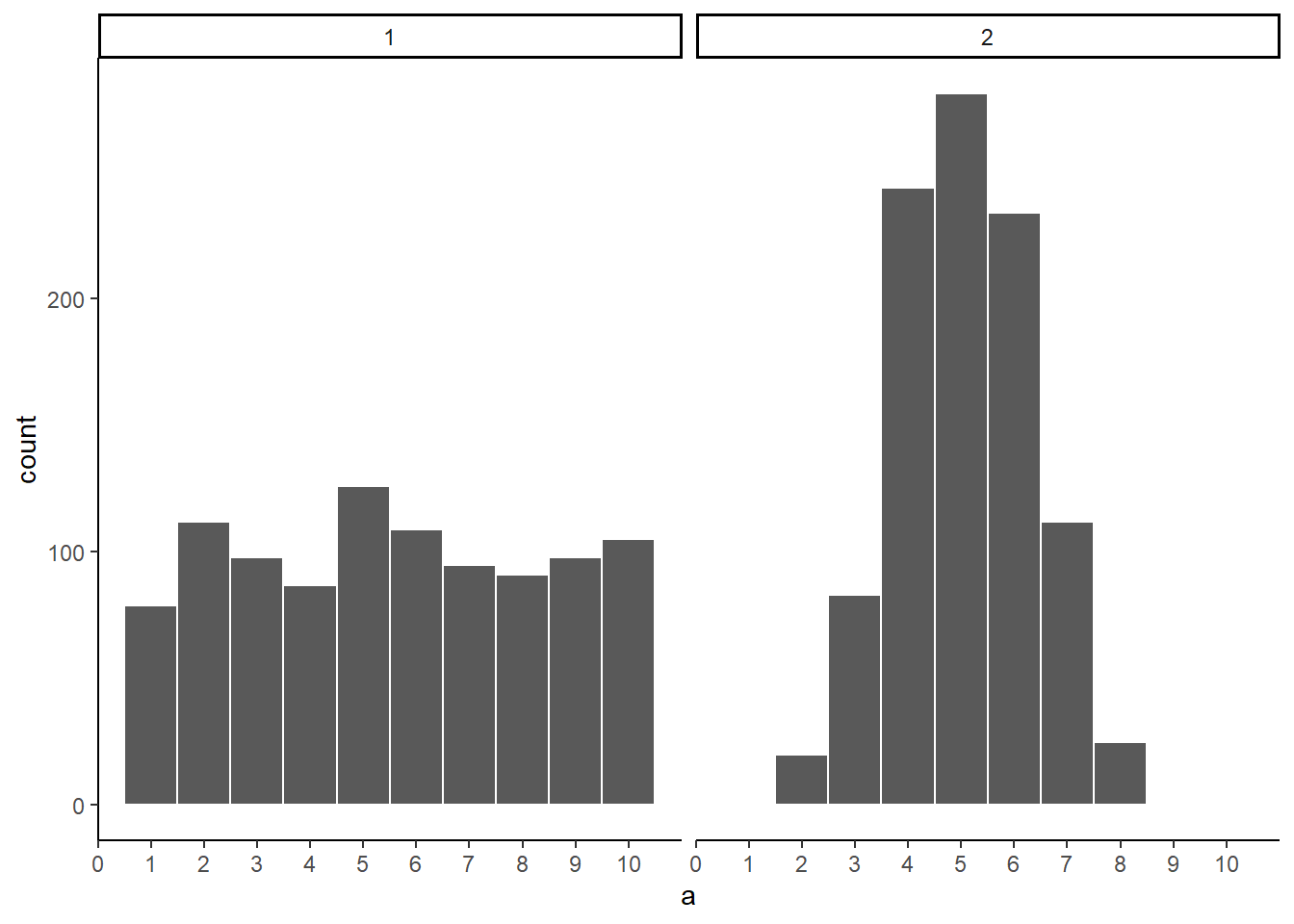
Figure 5.10: Which of these samples came from a uniform distribution?
Now that we have increased N, we can see the pattern in each sample becomes more obvious. The histogram for sample 1 has bars near 100, not perfectly flat, but it resembles a uniform distribution. The histogram for sample 2 does not look flat at all. Instead, there the number five appears most of the time, and numbers on either side of five happen less and less.
Congratulations to Us! We have just made some statistical inferences without using formulas!
“We did?” Yes, by looking at our two samples we have inferred that sample 2 did not come from a uniform distribution. We have also inferred that sample 1 could have come form a uniform distribution. Fantastic. This is really all we will be doing for the rest of the course. We will be looking at some numbers, wondering where they came from, then we will arrange the numbers in such a way so that we can make an inference about where they came from. That’s it.
5.3 Is there a difference?
Let’s get back to experiments. In an experiment we want to know if our independent variable (our manipulation) causes a change in our dependent variable (measurement). If this occurs, then we will expect to see some differences in our measurement as a function of manipulation.
Consider the light switch example:
Light Switch Experiment: You manipulate the switch up (condition 1 of independent variable), light goes on (measurement). You manipulate the switch down (condition 2 of independent variable), light goes off (another measurement). The measurement (light) changes (goes off and on) as a function of the manipulation (moving switch up or down).
You can see the change in measurement between the conditions, it is as obvious as night and day. So, when you conduct a manipulation, and can see the difference (change) in your measure, you can be pretty confident that your manipulation is causing the change.
note: to be cautious we can say “something” about your manipulation is causing the change, it might not be what you think it is if your manipulation is very complicated and involves lots of moving parts.
5.3.1 Chance can produce differences
Do you think random chance can produce the appearance of differences, even when there really aren’t any? I hope so. We have already shown that the process of sampling numbers from a distribution is a chancy process that produces different samples. Different samples are different, so yes, chance can produce differences. This can muck up our interpretation of experiments.
Let’s conduct a fictitious experiment where we expect to find no differences, because we will manipulate something that shouldn’t do anything. Here’s the set-up:
You are the experimenter standing in front of a gumball machine. It is very big, has thousands of gumballs. 50% of the gumballs are green, and 50% are red. You want to find out if picking gumballs with your right hand vs. your left hand will cause you to pick more green gumballs. Plus, you will be blindfolded the entire time. The independent variable is Hand: right hand vs. left hand. The dependent variable is the measurement of the color of each gumball.
You run the experiment as follows. 1) put on blind fold. 2) pick 10 gumballs randomly with left hand, set them aside. 3) pick 10 gumballs randomly with right hand, set them aside. 4) count the number of green and red gumballs chosen by your left hand, and count the number of green and red gumballs chosen by your right hand. Hopefully you will agree that your hands will not be able to tell the difference between the gumballs. If you don’t agree, we will further stipulate the gumballs are completely identical in every way except their color, so it would be impossible to tell them apart using your hands. So, what should happen in this experiment?
“Umm, maybe you get 5 red gum balls and 5 green balls from your left hand, and also from your right hand?” Sort of yes, this is what you would usually get. But, it is not all that you can get. Here is some data showing what happened from one pretend experiment:
| hand | gumball |
|---|---|
| left | 0 |
| left | 1 |
| left | 1 |
| left | 1 |
| left | 1 |
| left | 0 |
| left | 1 |
| left | 1 |
| left | 0 |
| left | 1 |
| right | 1 |
| right | 0 |
| right | 0 |
| right | 1 |
| right | 0 |
| right | 0 |
| right | 0 |
| right | 1 |
| right | 1 |
| right | 1 |
“What am I looking at here.” This is a long-format table. Each row is one gumball. The first column tells you what hand was used. The second column tells you what kind of gumball. We will say 1s stand for green gum balls, and 0s stand for red gumballs. So, did your left hand cause you to pick more green gumballs than your right hand?
It would be easier to look at the data using a bar graph. To keep things simple, we will only count green gumballs (the other gumballs must be red). So, all we need to do is sum up the 1s. The 0s won’t add anything.
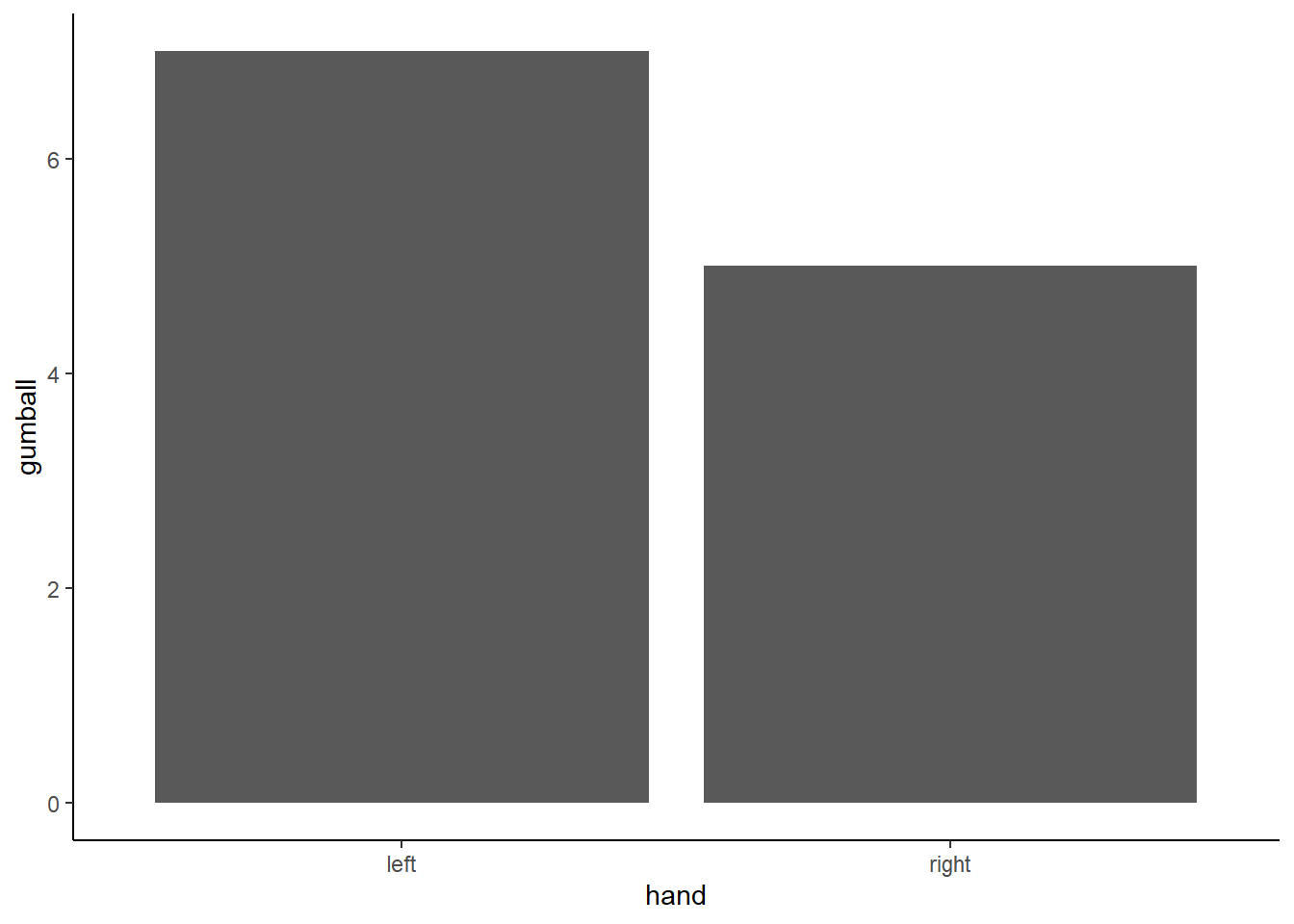
Figure 5.11: Counts of gumballs picked
Oh look, the bars are not the same. One hand picked more green gum balls than the other. Does this mean that one of your hands secretly knows how to find green gumballs? No, it’s just another case of sampling error, that thing we call luck or chance. The difference here is caused by chance, not by the manipulation (which hand you use). Major problem for inference alert. We run experiments to look for differences so we can make inferences about whether our manipulations cause change in our measures. Now we know that we can find differences by chance. How can we know if a difference is real, or just caused by chance?
5.3.2 Differences due to chance can be simulated
Remember when we showed that chance can produce correlations. We also showed that chance is restricted in its ability to produce correlations. For example, chance more often produces weak correlations than strong correlations. Remember the window of chance? We found out before that correlations falling outside the window of chance were very unlikely. We can do the same thing for differences. Let’s find out just what chance can do in our experiment. Once we know what chance is capable of we will be in a better position to judge whether our manipulation caused a difference, or whether it could have been chance.
The first thing to do is pretend you conduct the gumball experiment 10 times in a row. This will produce 10 different sets of results. For each of them we can make a bar graph, and look at whether the left hand chose more green gumballs than red gumballs. It looks like this:
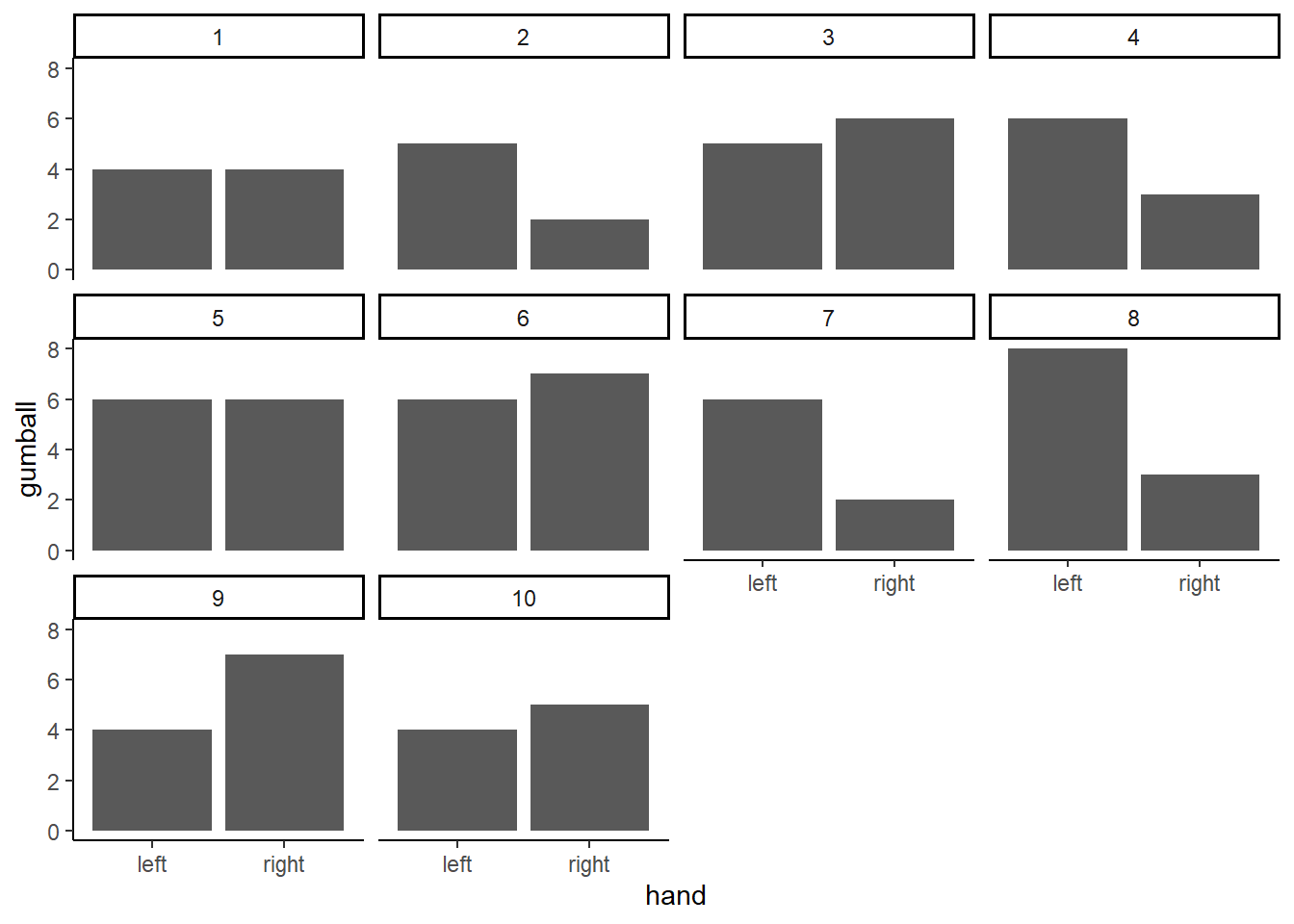
Figure 5.12: 10 simulated replications of picking gumballs. Each replication gives a slightly different answer. Any difference are all due to chance, or sampling error. This shows that chance alone can produce differences, just by the act of sampling
These 10 experiments give us a better look at what chance can do. It should also mesh well with your expectations. If everything is left up to chance (as we have made it so), then sometimes your left hand will choose more green balls, sometimes your right hand will choose more green gumballs, and sometimes they will choose the same amount of gumballs. Right? Right.
5.4 Chance makes some differences more likely than others
OK, we have seen that chance can produce differences here. But, we still don’t have a good idea about what chance usually does and doesn’t do. For example, if we could find the window of opportunity here, we would be able find out that chance usually does not produce differences of a certain large size. If we knew what the size was, then if we ran experiment and our difference was bigger than what chance can do, we could be confident that chance did not produce our difference.
Let’s use the word difference some more, because it will be helpful. In fact, let’s think about our measure of green balls in terms of a difference. For example, in each experiment we counted the green balls for the left and right hand. What we really want to know is if there is a difference between them. So, we can calculate the difference score. Let’s decide that difference score = # of green gumballs in left hand - # of green gumballs in right hand. Now, we can redraw the 10 bar graphs from above. But this time we will only see one bar for each experiment. This bar will show the difference in number of green gumballs.
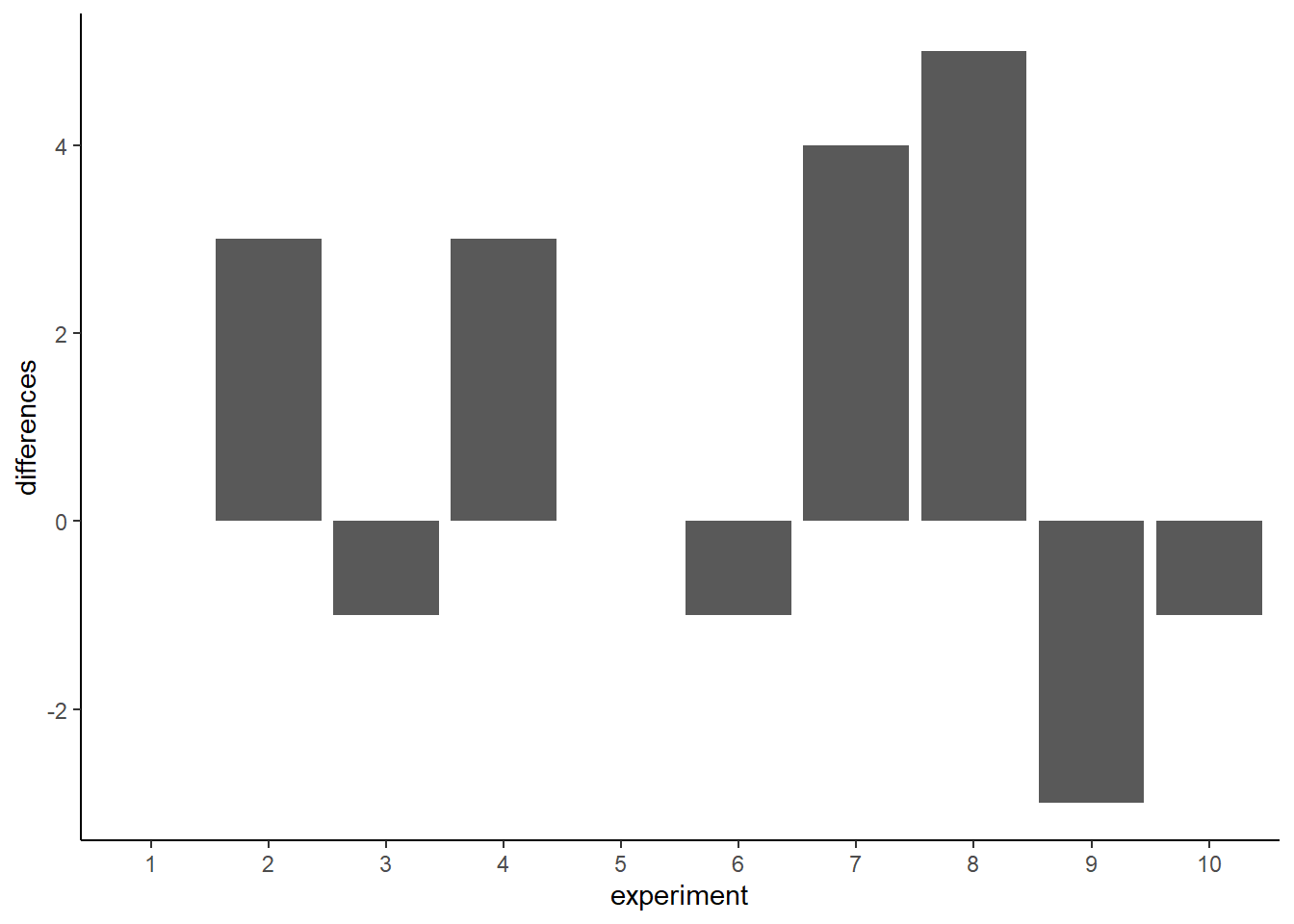
Figure 5.13: A look at the differences between number of each kind of gumball for the different replications. The difference should be zero, but sampling error produces non-zero differences
Missing bars mean that there were an equal number of green gumballs chosen by the left and right hands (difference score is 0). A positive value means that more green gumballs were chosen by the left than right hand. A negative value means that more green gumballs were chosen by the right than left hand. Note that if we decided (and we get to decide) to calculate the difference in reverse (right hand - left hand), the signs of the differences scores would flip around.
We are starting to see more of the differences that chance can produce. The difference scores are mostly between -2 to +2. We could get an even better impression by running this pretend experiment 100 times instead of only 10 times. How about we do that.
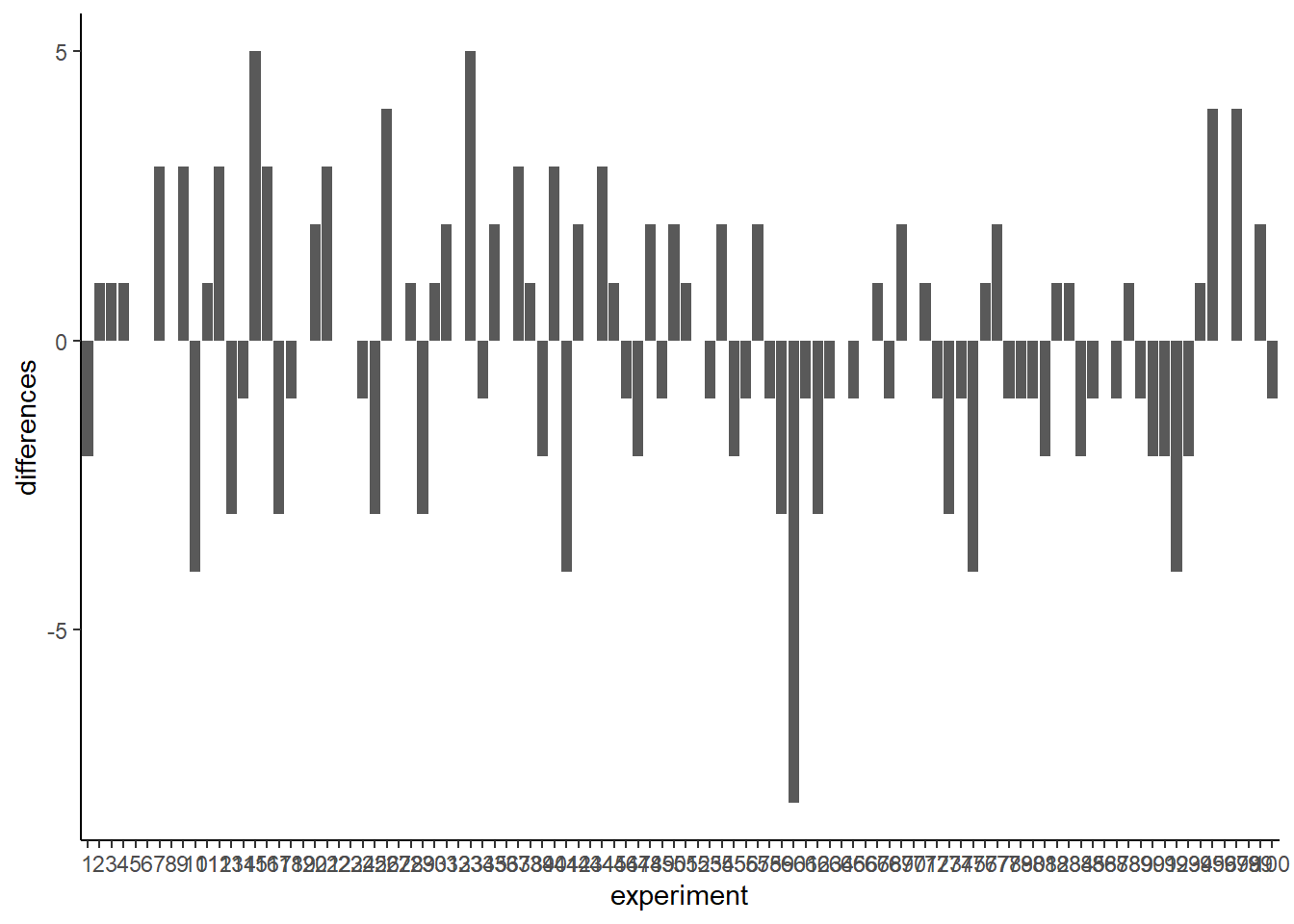
Figure 5.14: Replicating the sampling 100 times, and looking at the differences each time. There are mnay kinds of differences that chance alone can produce
Ooph, we just ran so many simulated experiments that the x-axis is unreadable, but it goes from 1 to 100. Each bar represents the difference of number of green balls chosen randomly by the left or right hand. Beginning to notice anything? Look at the y-axis, this shows the size of the difference. Yes, there are lots of bars of different sizes, this shows us that many kinds of differences do occur by chance. However, the y-axis is also restricted. It does not go from -10 to +10. Big differences greater than 5 or -5 don’t happen very often.
Now that we have a method for simulating differences due to chance, let’s run 10,000 simulated experiments. But, instead of plotting the differences in a bar graph for each experiment, how about we look at the histogram of difference scores. This will give us a clearer picture about which differences happen most often, and which ones do not. This will be another window into chance. The chance window of differences.
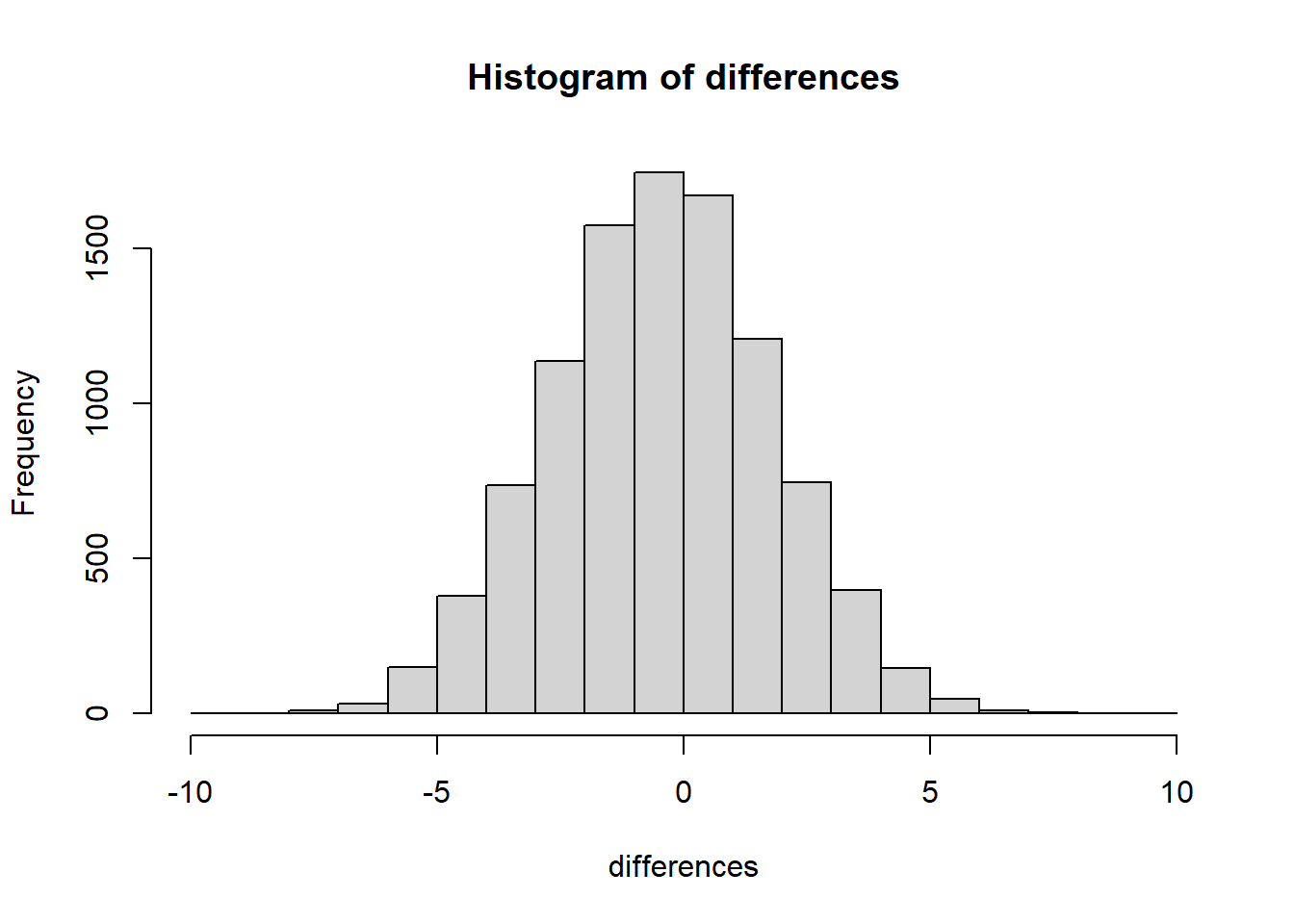
Figure 5.15: A histogram of the differences obtained by chance over 10,000 replications. The most frequency difference is 0, which is what we expect by chance. But the differences can be as large as -10 or +10. Larger differences occur less often by chance. Chance can’t do everything
Our computer simulation allows us to force chance to operate hundreds of times, each time it produces a difference. We record the difference, then at the end of the simulation we plot the histogram of the differences. The histogram begins to show us the where the differences came from. Remember the idea that numbers come from a distribution, and the distribution says how often each number occurs. We are looking at one of these distributions. It is showing us that chance produces some differences more often than others. First, chance usually produces 0 differences, that’s the biggest bar in the middle. Chance also produces larger differences, but as the differences get larger (positive or negative), they occur less frequently. The shape of this histogram is your chance window, it tells you what chance can do, it tells you what chance usually does, and what it usually does not do.
You can use this chance window to help you make inferences. If you ran yourself in the gumball experiment and found that your left hand chose 2 more green gumballs than red gumballs, would you conclude that you left hand was special, and caused you to choose more green gumballs? Hopefully not. You could look at the chance window and see that differences of size +2 do happen fairly often by chance alone. You should not be surprised if you got a +2 difference. However, what if your left chose 5 more green gumballs than red gumballs. Well, chance doesn’t do this very often, you might think something is up with your left hand. If you got a whopping 9 more green gumballs than red gumballs, you might really start to wonder. This is the kind of thing that could happen (it’s possible), but virtually never happens by chance. When you get things that almost never happen by chance, you can be more confident that the difference reflects a causal force that is not chance.
5.5 The Crump Test
We are going to be doing a lot of inference throughout the rest of this course. Pretty much all of it will come down to one question. Did chance produce the differences in my data? We will be talking about experiments mostly, and in experiments we want to know if our manipulation caused a difference in our measurement. But, we measure things that have natural variability, so every time we measure things we will always find a difference. We want to know if the difference we found (between our experimental conditions) could have been produced by chance. If chance is a very unlikely explanation of our observed difference, we will make the inference that chance did not produce the difference, and that something about our experimental manipulation did produce the difference. This is it (for this textbook).
Statistics is not only about determining whether chance could have produced a pattern in the observed data. The same tools we are talking about here can be generalized to ask whether any kind of distribution could have produced the differences. This allows comparisons between different models of the data, to see which one was the most likely, rather than just rejecting the unlikely ones (e.g., chance). But, we’ll leave those advanced topics for another textbook.
This chapter is about building intuitions for making these kinds of inferences about the role of chance in your data. It’s not clear to me what are the best things to say, to build up your intuitions for how to do statistical inference. So, this chapter tries different things, some of them standard, and some of them made up. What you are about to read, is a made up way of doing statistical inference, without using the jargon that we normally use to talk about it. The goal is to do things without formulas, and without probabilities, and just work with some ideas using simulations to see what happens. We will look at what chance can do, then we will talk about what needs to happen in your data in order for you to be confident that chance didn’t do it.
5.5.1 Intuitive methods
Warning, this is an unofficial statistical test made up by Matt Crump. It makes sense to him (me), and if it turns out someone else already made this up, then Crump didn’t do his homework, and we will change the name of this test to it’s original author. The point of this test is to show how simple operations that you already understand can be used to create a tool for inference. This test is not complicated, it uses
- Sampling numbers randomly from a distribution
- Adding, subtracting
- Division, to find the mean
- Counting
- Graphing and drawing lines
- NO FORMULAS
5.5.2 Part 1: Frequency based intuition about occurence
Question: How many times does something need to happen, for it to happen a lot? Or, how many times does something need to happen for it to happen not very much, or even really not at all? Small enough for you to not worry about it at all happening to you?
Would you go outside everyday if you thought that you would get hit by lightning 1 out of 10 times? I wouldn’t. You’d probably be hit by lightning more than once per month, you’d be dead pretty quickly. 1 out of 10 is a lot (to me, maybe not to you, there’s no right answer here).
Would you go outside everyday if you thought that you would get hit by lightning 1 out of every 100 days? Jeez, that’s a tough one. What would I even do? If I went out everyday, I’d probably be dead in a year! Maybe I would go out 2 or 3 times per year, I’m risky like that, but I’d probably live longer. It would massively suck.
Would you go outside everyday if you thought you would get hit by lightning 1 out of every 1000 days? Well, you’d probably be dead in 3-6 years if you did that. Are you a gambler? Maybe go out once per month, still sucks.
Would you go outside everyday if you thought lightning would get you 1 out every 10,000 days? 10,000 is a bigger number, harder to think about. It’s about once every 27 years. Ya, I’d probably go out 150 days per year, and live a bit longer if I can.
Would you go outside everyday if you thought lightning would get you 1 out every 100,000 days? 100,000 is a bigger number, harder to think about. How many years is that? It’s about 273 years. With those odds, I’d probably go out all the time and forget about being hit by lightning. It doesn’t happen very often, and if it does, c’est la vie.
The point of considering these questions is to get a sense for yourself of what happens a lot, and what doesn’t happen a lot, and how you would make important decisions based on what happens a lot and what doesn’t.
5.5.3 Part 2: Simulating chance
This next part could happen a bunch of ways, I’ll make loads of assumptions that I won’t defend, and I won’t claim the Crump test has problems. I will claim it helps us make an inference about whether chance could have produced some differences in data. We’ve already been introduced to simulating things, so we’ll do that again. Here is what we will do. I am a cognitive psychologist who happens to be measuring X. Because of prior research in the field, I know that when I measure X, my samples will tend to have a particular mean and standard deviation. Let’s say the mean is usually 100, and the standard deviation is usually 15. In this case, I don’t care about using these numbers as estimates of the population parameters, I’m just thinking about what my samples usually look like. What I want to know is how they behave when I sample them. I want to see what kind of samples happen a lot, and what kind of samples don’t happen a lot. Now, I also live in the real world, and in the real world when I run experiments to see what changes X, I usually only have access to some number of participants, who I am very grateful too, because they participate in my experiments. Let’s say I usually can run 20 subjects in each condition in my experiments. Let’s keep the experiment simple, with two conditions, so I will need 40 total subjects.
I would like to learn something to help me with inference. One thing I would like to learn is what the sampling distribution of the sample mean looks like. This distribution tells me what kinds of mean values happen a lot, and what kinds don’t happen very often. But, I’m actually going to skip that bit. Because what I’m really interested in is what the sampling distribution of the difference between my sample means looks like. After all, I am going to run an experiment with 20 people in one condition, and 20 people in the other. Then I am going to calculate the mean for group A, and the mean for group B, and I’m going to look a the difference. I will probably find a difference, but my question is, did my manipulation cause this difference, or is this the kind of thing that happens a lot by chance. If I knew what chance can do, and how often it produces differences of particular sizes, I could look at the difference I observed, then look at what chance can do, and then I can make a decision! If my difference doesn’t happen a lot (we’ll get to how much not a lot is in a bit), then I might be willing to believe that my manipulation caused a difference. If my difference happens all the time by chance alone, then I wouldn’t be inclined to think my manipulation caused the difference, because it could have been chance.
So, here’s what we’ll do, even before running the experiment. We’ll do a simulation. We will sample numbers for group A and Group B, then compute the means for group A and group B, then we will find the difference in the means between group A and group B. But, we will do one very important thing. We will pretend that we haven’t actually done a manipulation. If we do this (do nothing, no manipulation that could cause a difference), then we know that only sampling error could cause any differences between the mean of group A and group B. We’ve eliminated all other causes, only chance is left. By doing this, we will be able to see exactly what chance can do. More importantly, we will see the kinds of differences that occur a lot, and the kinds that don’t occur a lot.
Before we do the simulation, we need to answer one question. How much is a lot? We could pick any number for a lot. I’m going to pick 10,000. That is a lot. If something happens only 1 times out 10,000, I am willing to say that is not a lot.
OK, now we have our number, we are going to simulate the possible mean differences between group A and group B that could arise by chance. We do this 10,000 times. This gives chance a lot of opportunity to show us what it does do, and what it does not do.
This is what I did: I sampled 20 numbers into group A, and 20 into group B. The numbers both came from the same normal distribution, with mean = 100, and standard deviation = 15. Because the samples are coming from the same distribution, we expect that on average they will be similar (but we already know that samples differ from one another). Then, I compute the mean for each sample, and compute the difference between the means. I save the mean difference score, and end up with 10,000 of them. Then I draw a histogram. It looks like this:
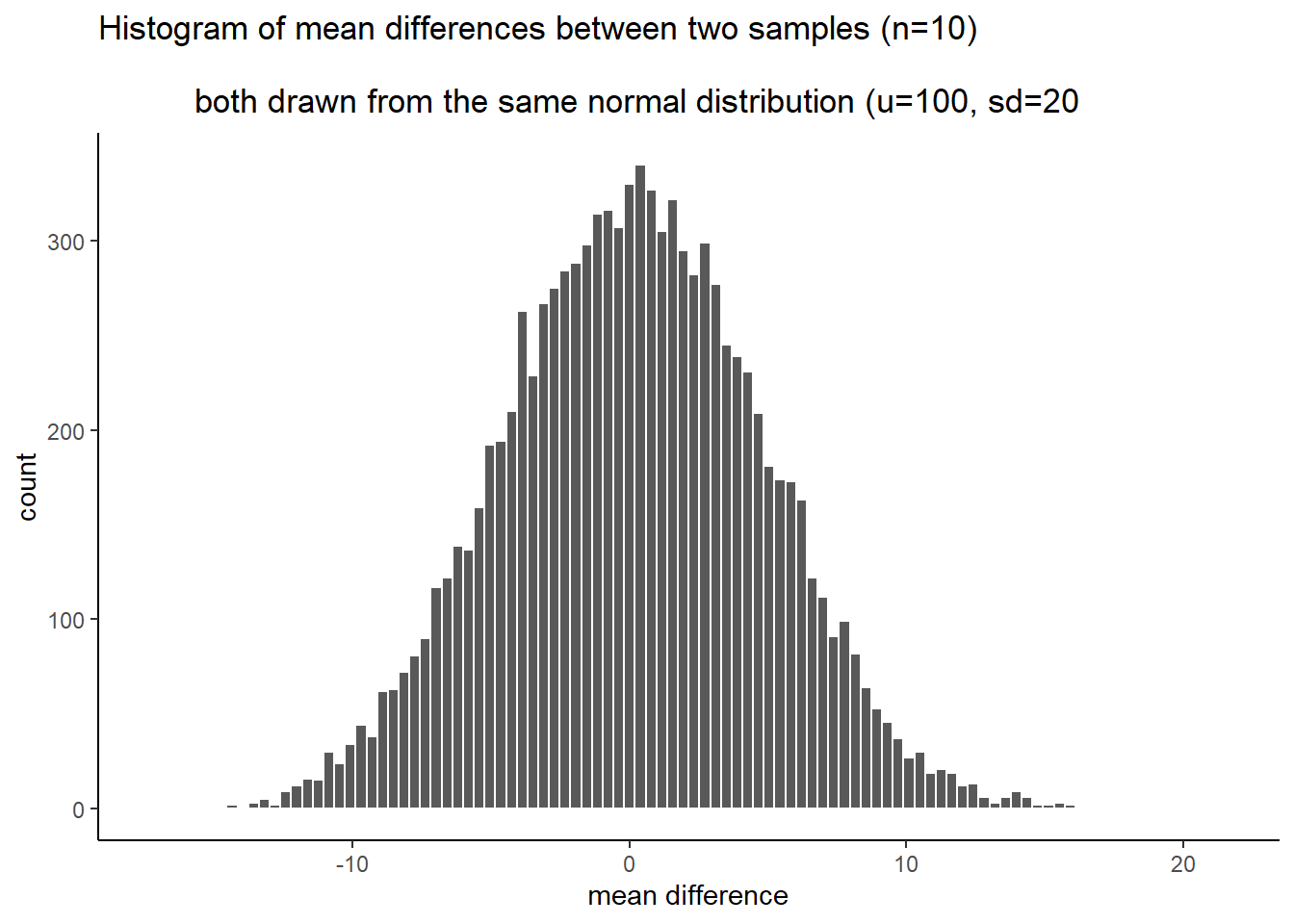
Figure 5.16: Histogram of mean differences arising by chance
Sidenote: Of course, we might recognize that chance could do a difference greater than 15. We just didn’t give it the opportunity. We only ran the simulation 10,000 times. If we ran it on million times, maybe a difference greater than 20 would happen a couple times. If we ran it a bazillion gazillion times, maybe a difference greater than 30 would happen a couple times. If we go out to infinity, then chance might produce all sorts of bigger differences once in a while. But, we’ve already decided that 1/10,000 is not a lot. So things that happen 0/10,000 times, like differences greater than 15, just don’t happen very much.
Now we can see what chance can do to the size of our mean difference. The x-axis shows the size of the mean difference. We took our samples from the sample distribution, so the difference between them should usually be 0, and that’s what we see in the histogram.
Pause for a second. Why should the mean differences usually be zero, wasn’t the population mean = 100, shouldn’t they be around 100? No. The mean of group A will tend to be around 100, and the mean of group B will tend be around 100. So, the difference score will tend to be 100-100 = 0. That is why we expect a mean difference of zero when the samples are drawn from the same population.
So, differences near zero happen the most, that’s good, that’s what we expect. Bigger or smaller differences happen increasingly less often. Differences greater than 15 or -15 never happen at all. For our purposes, it looks like chance only produces differences between -15 to 15.
OK, let’s ask a couple simple questions. What was the biggest negative number that occurred in the simulation? We’ll use R for this. All of the 10,000 difference scores are stored in a variable I made called difference. If we want to find the minimum value, we use the min function. Here’s the result.
min(difference)## [1] -17.23661OK, so what was the biggest positive number that occurred? Let’s use the max function to find out. It finds the biggest (maximum) value in the variable. FYI, we’ve just computed the range, the minimum and maximum numbers in the data. Remember we learned that before. Anyway, here’s the max.
max(difference)## [1] 21.18388Both of these extreme values only occurred once. Those values were so rare we couldn’t even see them on the histogram, the bar was so small. Also, these biggest negative and positive numbers are pretty much the same size if you ignore their sign, which makes sense because the distribution looks roughly symmetrical.
So, what can we say about these two numbers for the min and max? We can say the min happens 1 times out of 10,000. We can say the max happens 1 times out of 10,000. Is that a lot of times? Not to me. It’s not a lot.
So, how often does a difference of 30 (much larger larger than the max) occur out of 10,000. We really can’t say, 30s didn’t occur in the simulation. Going with what we got, we say 0 out of 10,000. That’s never.
We’re about to move into part three, which involves drawing decision lines and talking about them. The really important part about part 3 is this. What would you say if you ran this experiment once, and found a mean difference of 30? I would say it happens 0 times of out 10,000 by chance. I would say chance did not produce my difference of 30. That’s what I would say. We’re going to expand upon this right now.
5.5.4 Part 3: Judgment and Decision-making
Remember, we haven’t even conducted an experiment. We’re just simulating what could happen if we did conduct an experiment. We made a histogram. We can see that chance produces some differences more than others, and that chance never produced really big differences. What should we do with this information?
What we are going to do is talk about judgment and decision making. What kind of judgment and decision making? Well, when you finally do run an experiment, you will get two means for group A and B, and then you will need to make some judgments, and perhaps even a decision, if you are so inclined. You will need to judge whether chance (sampling error) could have produced the difference you observed. If you judge that it did it not, you might make the decision to tell people that your experimental manipulation actually works. If you judge that it could have been chance, you might make a different decision. These are important decisions for researchers. Their careers can depend on them. Also, their decisions matter for the public. Nobody wants to hear fake news from the media about scientific findings.
So, what we are doing is preparing to make those judgments. We are going to draw up a plan, before we even see the data, for how we will make judgments and decisions about what we find. This kind of planning is extremely important, because we discuss in part 4, that your planning can help you design an even better experiment than the one you might have been intending to run. This kind of planning can also be used to interpret other people’s results, as a way of double-checking checking whether you believe those results are plausible.
The thing about judgement and decision making is that reasonable people disagree about how to do it, unreasonable people really disagree about it, and statisticians and researchers disagree about how to do it. I will propose some things that people will disagree with. That’s OK, these things still make sense. And, the disagreeable things point to important problems that are very real for any “real” statistical inference test.
Let’s talk about some objective facts from our simulation of 10,000 things that we definitely know to be true. For example, we can draw some lines on the graph, and label some different regions. We’ll talk about two kinds of regions.
- Region of chance. Chance did it. Chance could have done it
- Region of not chance. Chance didn’t do it. Chance couldn’t have done it.
The regions are defined by the minimum value and the maximum value. Chance never produced a smaller or bigger number. The region inside the range is what chance did do, and the the region outside the range on both sides is what chance never did. It looks like this:
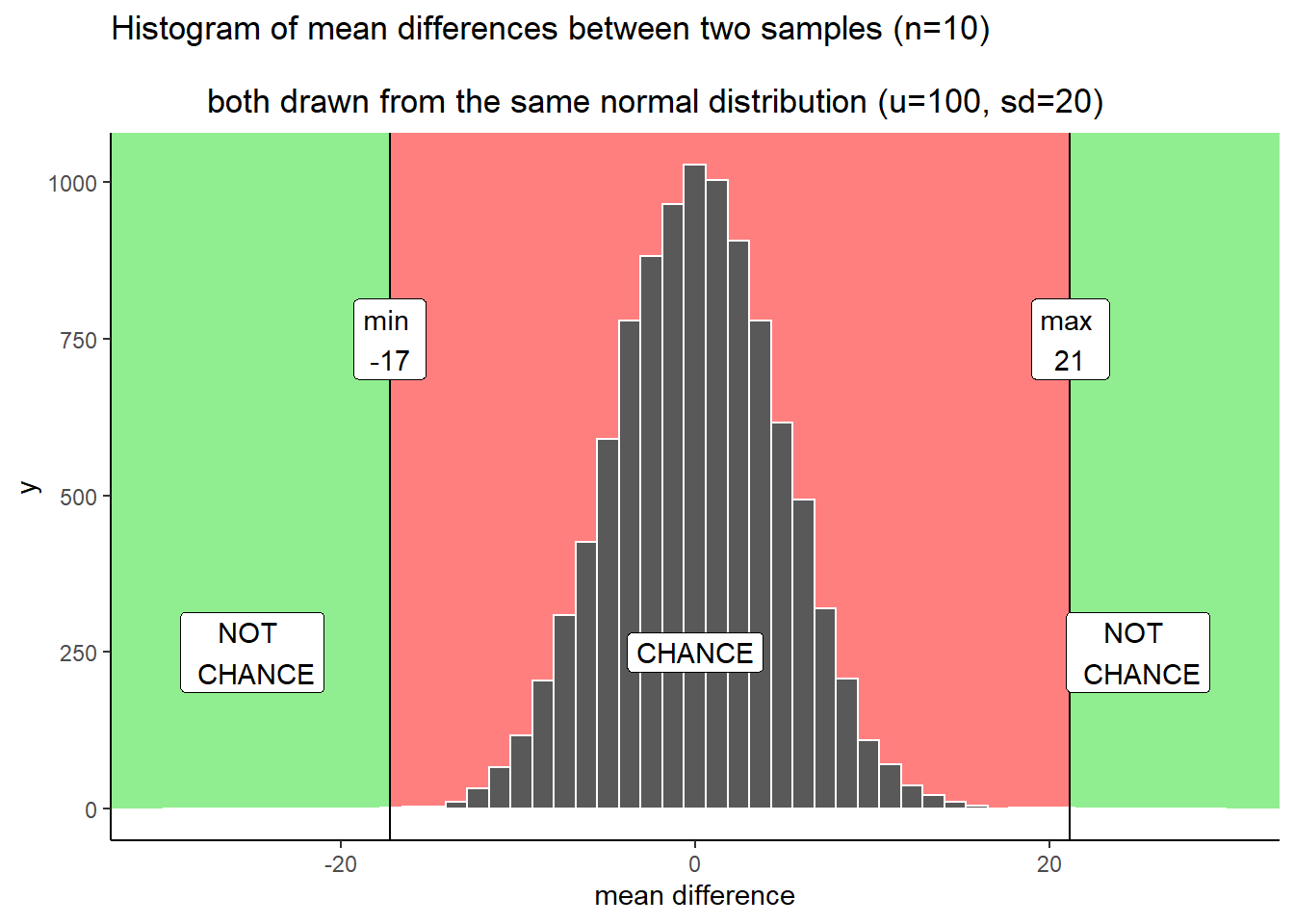
Figure 5.17: Applying decision boundaries to the histogrm of mean differences. The boundaries identify what differences chance did or did not produce in the simulation
We have just drawn some lines, and shaded some regions, and made one plan we could use to make decisions. How would the decisions work. Let’s say you ran the experiment and found a mean difference between groups A and B of 25. Where is 25 in the figure? It’s in the green part. What does the green part say? NOT CHANCE. What does this mean. It means chance never made a difference of 25. It did that 0 out of 10,000 times. If we found a difference of 25, perhaps we could confidently conclude that chance did not cause the difference. If I found a difference of 25 with this kind of data, I’d be pretty confident that my experimental manipulation caused the difference, because obviously chance never does.
What about a difference of +10? That’s in the red part, where chance lives. Chance could have done a difference of +10 because we can see that it did do that. The red part is the window of what chance did in our simulation. Anything inside the window could have been a difference caused by chance. If I found a difference of +10, I’d say, coulda been chance. I would not be very confident that my experimental manipulation caused the difference.
Statistical inference could be this easy. The number you get from your experiment could be in the chance window (then you can’t rule out chance as a cause), or it could be outside the chance window (then you can rule out chance). Case closed. Let’s all go home.
5.5.4.1 Grey areas
So what’s the problem? Depending on who you are, and what kinds of risks you’re willing to take, there might not be a problem. But, if you are just even a little bit risky then there is a problem that makes clear judgments about the role of chance difficult. We would like to say chance did or did not cause our difference. But, we’re really always in the position of admitting that it could have sometimes, or wouldn’t have most times. These are wishy washy statements, they are in between yes or no. That’s OK. Grey is a color too, let’s give grey some respect.
“What grey areas are you talking about?, I only see red or green, am I grey blind?” Let’s look at where some grey areas might be. I say might be, because people disagree about where the grey is. People have different comfort levels with grey. Here’s my opinion on some clear grey areas.
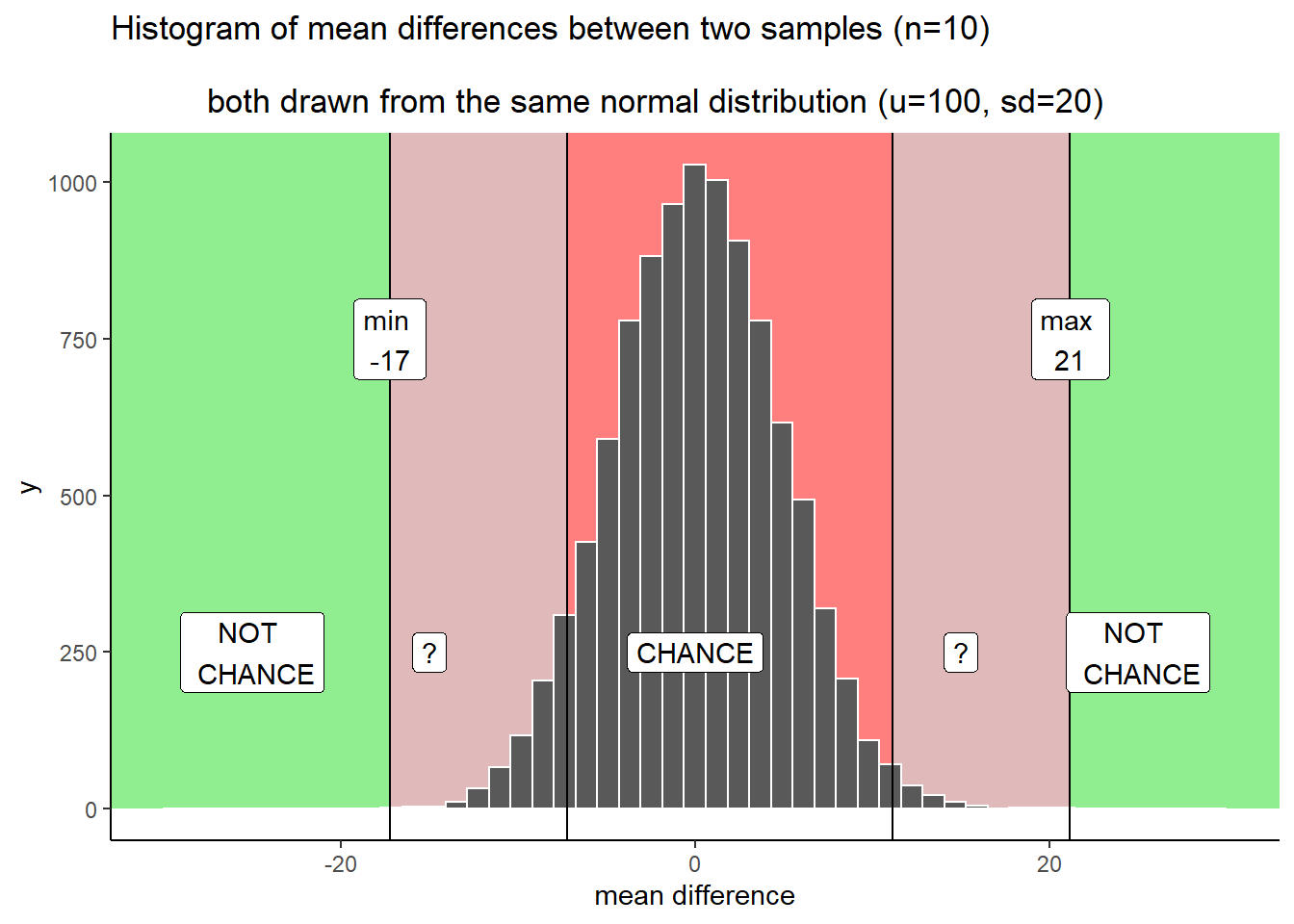
Figure 5.18: The question marks refer to an area where you have some uncertainty. Differences inside the question mark region do not happen very often by chance. When you find differences of these sizes, should you reject the idea that chance caused your difference? You will always have some uncertainty associated with this decision because it is clear that chance could have caused the difference. But, chance usually does not produce differences of these sizes
I made two grey areas, and they are reddish grey, because we are still in the chance window. There are question marks (?) in the grey areas. Why? The question marks reflect some uncertainty that we have about those particular differences. For example, if you found a difference that was in a grey area, say a 15. 15 is less than the maximum, which means chance did create differences of around 15. But, differences of 15 don’t happen very often.
What can you conclude or say about this 15 you found? Can you say without a doubt that chance did not produce the difference? Of course not, you know that chance could have. Still, it’s one of those things that doesn’t happen a lot. That makes chance an unlikely explanation. Instead of thinking that chance did it, you might be willing to take a risk and say that your experimental manipulation caused the difference. You’d be making a bet that it wasn’t chance…but, could be a safe bet, since you know the odds are in your favor.
You might be thinking that your grey areas aren’t the same as the ones I’ve drawn. Maybe you want to be more conservative, and make them smaller. Or, maybe you’re more risky, and would make them bigger. Or, maybe you’d add some grey area going in a little bit to the green area (after all, chance could probably produce some bigger differences sometimes, and to avoid those you would have to make the grey area go a bit into the green area).
Another thing to think about is your decision policy. What will you do, when your observed difference is in your grey area? Will you always make the same decision about the role of chance? Or, will you sometimes flip-flop depending on how you feel. Perhaps, you think that there shouldn’t be a strict policy, and that you should accept some level of uncertainty. The difference you found could be a real one, or it might not. There’s uncertainty, hard to avoid that.
So let’s illustrate one more kind of strategy for making decisions. We just talked about one that had some lines, and some regions. This makes it seem like we can either rule out, or not rule out the role of chance. Another way of looking at things is that everything is a different shade of grey. It looks like this:
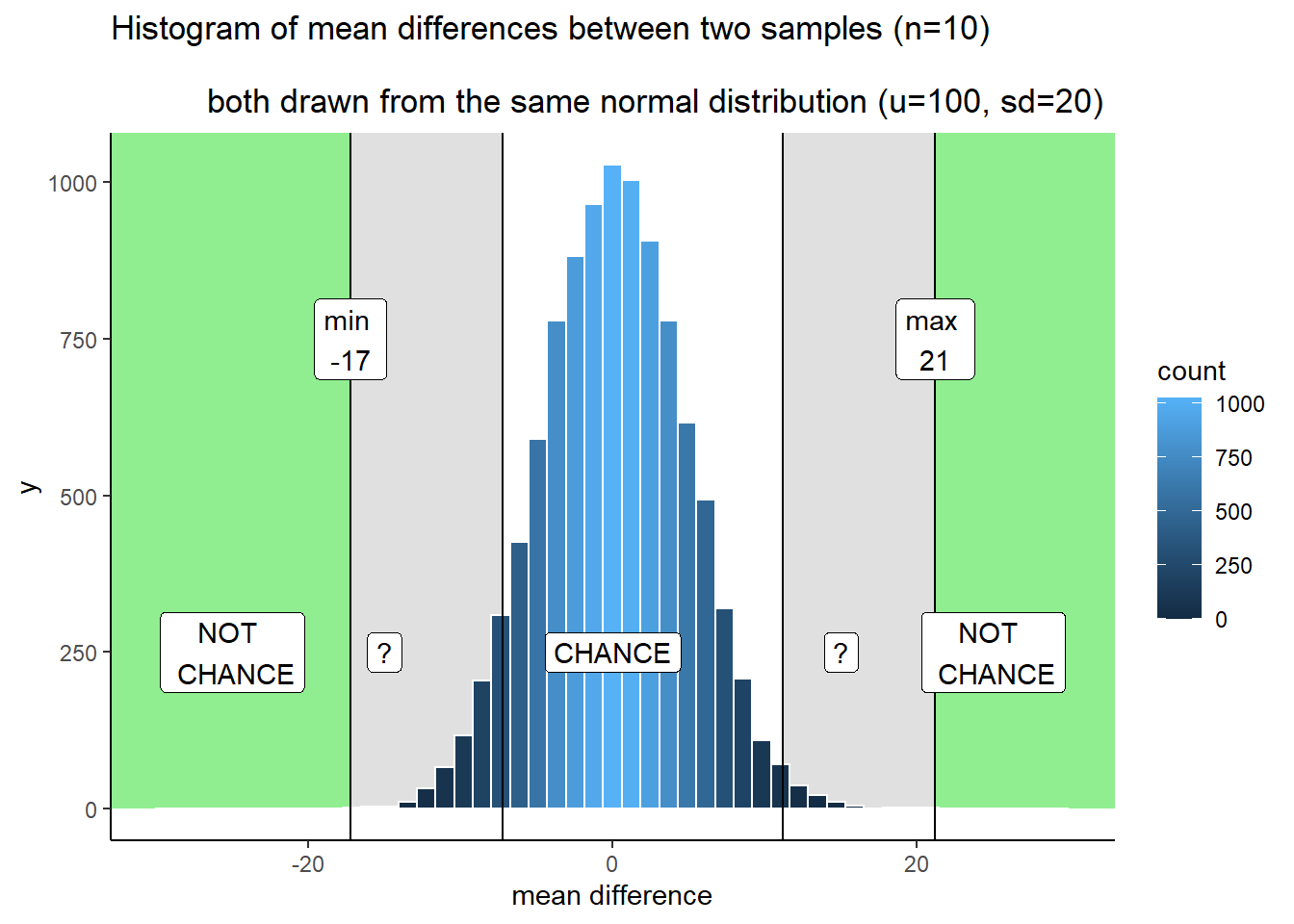
Figure 5.19: The shading of the blue bars indicates levels of confidence in whether a difference could have been produced by chance. Darker bars represent increased confidence that the difference was not produced by chance. Bars get darker as the mean difference increases in absolute value
OK, so I made it shades of blue (because it was easier in R). Now we can see two decision plans at the same time. Notice that as the bars get shorter, they also get become a darker stronger blue. The color can be used as a guide for your confidence. That is, your confidence in the belief that your manipulation caused the difference rather than chance. If you found a difference near a really dark bar, those don’t happen often by chance, so you might be really confident that chance didn’t do it. If you find a difference near a slightly lighter blue bar, you might be slightly less confident. That is all. You run your experiment, you get your data, then you have some amount of confidence that it wasn’t produced by chance. This way of thinking is elaborated to very interesting degrees in the Bayesian world of statistics. We don’t wade too much into that, but mention it a little bit here and there. It’s worth knowing it’s out there.
5.5.4.2 Making Bad Decisions
No matter how you plan to make decisions about your data, you will always be prone to making some mistakes. You might call one finding real, when in fact it was caused by chance. This is called a type I error, or a false positive. You might ignore one finding, calling it chance, when in fact it wasn’t chance (even though it was in the window). This is called a ** type II**, or a false negative.
How you make decisions can influence how often you make errors over time. If you are a researcher, you will run lots of experiments, and you will make some amount of mistakes over time. If you do something like the very strict method of only accepting results as real when they are in the “no chance” zone, then you won’t make many type I errors. Pretty much all of your result will be real. But, you’ll also make type II errors, because you will miss things real things that your decision criteria says are due to chance. The opposite also holds. If you are willing to be more liberal, and accept results in the grey as real, then you will make more type I errors, but you won’t make as many type II errors. Under the decision strategy of using these cutoff regions for decision-making there is a necessary trade-off. The Bayesian view get’s around this a little bit. Bayesians talk about updating their beliefs and confidence over time. In that view, all you ever have is some level of confidence about whether something is real, and by running more experiments you can increase or decrease your level of confidence. This, in some fashion, avoids some trade-off between type I and type II errors.
Regardless, there is another way to avoid type I and type II errors, and to increase your confidence in your results, even before you do the experiment. It’s called “knowing how to design a good experiment.”
5.5.5 Part 4: Experiment Design
We’ve seen what chance can do. Now we run an experiment. We manipulate something between groups A and B, get the data, calculate the group means, then look at the difference. Then we cross all of our finger and toes, and hope beyond hope that the difference is big enough to not be caused by chance. That’s a lot of hope.
Here’s the thing, we don’t often know how strong our manipulation is in the first place. So, even if it can cause a change, we don’t necessarily know how much change it can cause. That’s why we’re running the experiment. Many manipulations in Psychology are not strong enough to cause big changes. This is a problem for detecting these smallish causal forces. In our fake example, you could easily manipulate something that has a tiny influence, and will never push the mean difference past say 5 or 10. In our simulation, we need something more like a 15 or 17 or a 21, or hey, a 30 would be great, chance never does that. Let’s say your manipulation is listening to music or not listening to music. Music listening might change something about X, but if it only changes X by +5, you’ll never be able to confidently say it wasn’t chance. And, it’s not that easy to completely change music and make music super strong in the music condition so it really causes a change in X compared to the no music condition.
EXPERIMENT DESIGN TO THE RESCUE! Newsflash, it is often possible to change how you run your experiment so that it is more sensitive to smaller effects. How do you think we can do this? Here is a hint. It’s the stuff you learned about the sampling distribution of the sample mean, and the role of sample-size. What happens to the sampling distribution of the sample mean when N (sample size)? The distribution gets narrower and narrower, and starts to look the a single number (the hypothetical mean of the hypothetical population). That’s great. If you switch to thinking about mean difference scores, like the distribution we created in this test, what do you think will happen to that distribution as we increase N? It will will also shrink. As we increase N to infinity, it will shrink to 0. Which means that, when N is infinity, chance never produces any differences at all. We can use this.
For example, we could run our experiment with 20 subjects in each group. Or, we could decide to invest more time and run 40 subjects in each group, or 80, or 150. When you are the experimenter, you get to decide the design. These decisions matter big time. Basically, the more subjects you have, the more sensitive your experiment. With bigger N, you will be able to reliably detect smaller mean differences, and be able to confidently conclude that chance did not produce those small effects.
Check out this next set of histograms. All we are doing is the very same simulation as before, but this time we do it for different sample-sizes: 20, 40, 80, 160. We are doubling our sample-size across each simulation just to see what happens to the width of the chance window.
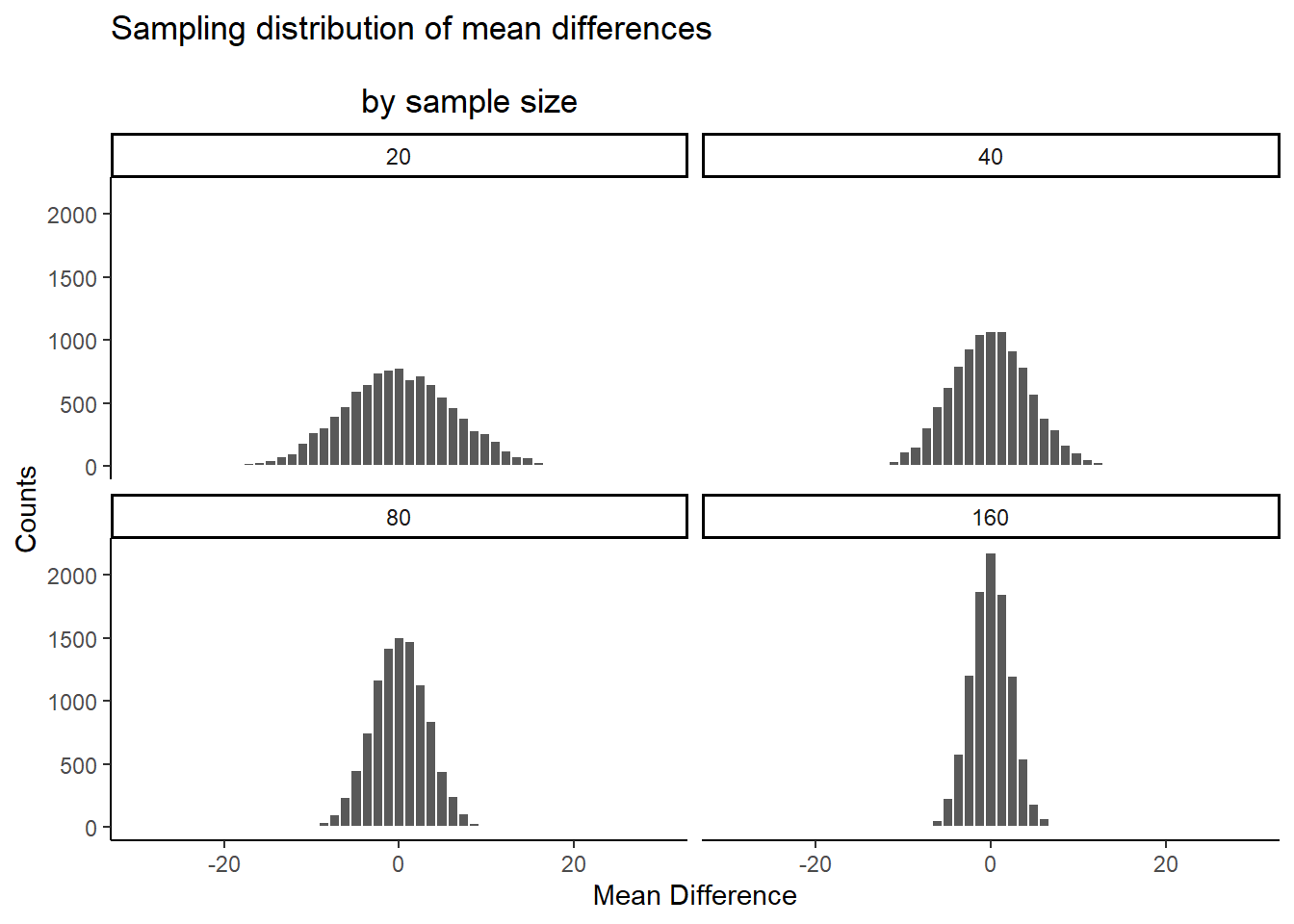
Figure 5.20: The range or width of the differences produced by chance shrinks as sample-size increases.
There you have it. The sampling distribution of the mean differences shrinks toward 0 as sample-size increases. This means if you run an experiment with a larger sample-size, you will be able to detect smaller mean differences, and be confident they aren’t due to chance. Let’s look at a table of the minimum and maximum values that chance produced across these four sample-sizes:
| sample_size | smallest | biggest |
|---|---|---|
| 20 | -25.056854 | 25.137921 |
| 40 | -18.688149 | 16.461410 |
| 80 | -11.740045 | 12.538743 |
| 160 | -8.367252 | 8.285351 |
The table is telling… The range of chance’s behavior is very wide for sample-size = 20, but about half as wide for sample-size = 160.
If it turns out your manipulation will cause a difference of +11, then what should you do? Run an experiment with 20 people? I hope not. If you did that, you could get +11s fairly often by chance. If you ran the experiment with 160 people, then you would definitely be able to say that +11 was not due to chance, it would be outside the range of what chance can do. You could even consider running the experiment with 80 subjects. A +11 there wouldn’t happen often by chance, and you’d be cost-effective, spending less time on the experiment.
The point is: the design of the experiment determines the sizes of the effects it can detect. If you want to detect a small effect. Make your sample size bigger. It’s really important to say this is not the only thing you can do. You can also make your cell-sizes bigger. For example, often times we take several measurements from a single subject. The more measurements you take (cell-size), the more stable your estimate of the subject’s mean. We discuss these issues more later. You can also make a stronger manipulation, when possible.
5.5.6 Part 5: I have the power
By the power of greyskull, I HAVE THE POWER - He-man
The last thing we’ll talk about here is something called power. In fact, we are going to talk about the concept of power, not actual power. It’s confusing now, but later we will define power in terms of some particular ideas about statistical inference. Here, we will just talk about the idea. And, we’ll show how to make sure your design has 100% power. Because, why not. Why run a design that doesn’t have the power?
The big idea behind power is the concept of sensitivity. The concept of sensitivity assumes that there is something to be sensitive to. That is, there is some real difference that can be measured. So, the question is, how sensitive is your experiment? We’ve already seen that the number of subjects (sample-size), changes the sensitivity of the design. More subjects = more sensitivity to smaller effects.
Let’s take a look at one more plot. What we will do is simulate a measure of sensitivity across a whole bunch of sample sizes, from 10 to 300. We’ll do this in steps of 10. For each simulation, we’ll compute the mean differences as we have done. But, rather than showing the histogram, we’ll just compute the smallest value and the largest value. This is a pretty good measure of the outer reach of chance. Then we’ll plot those values as a function of sample size and see what we’ve got.
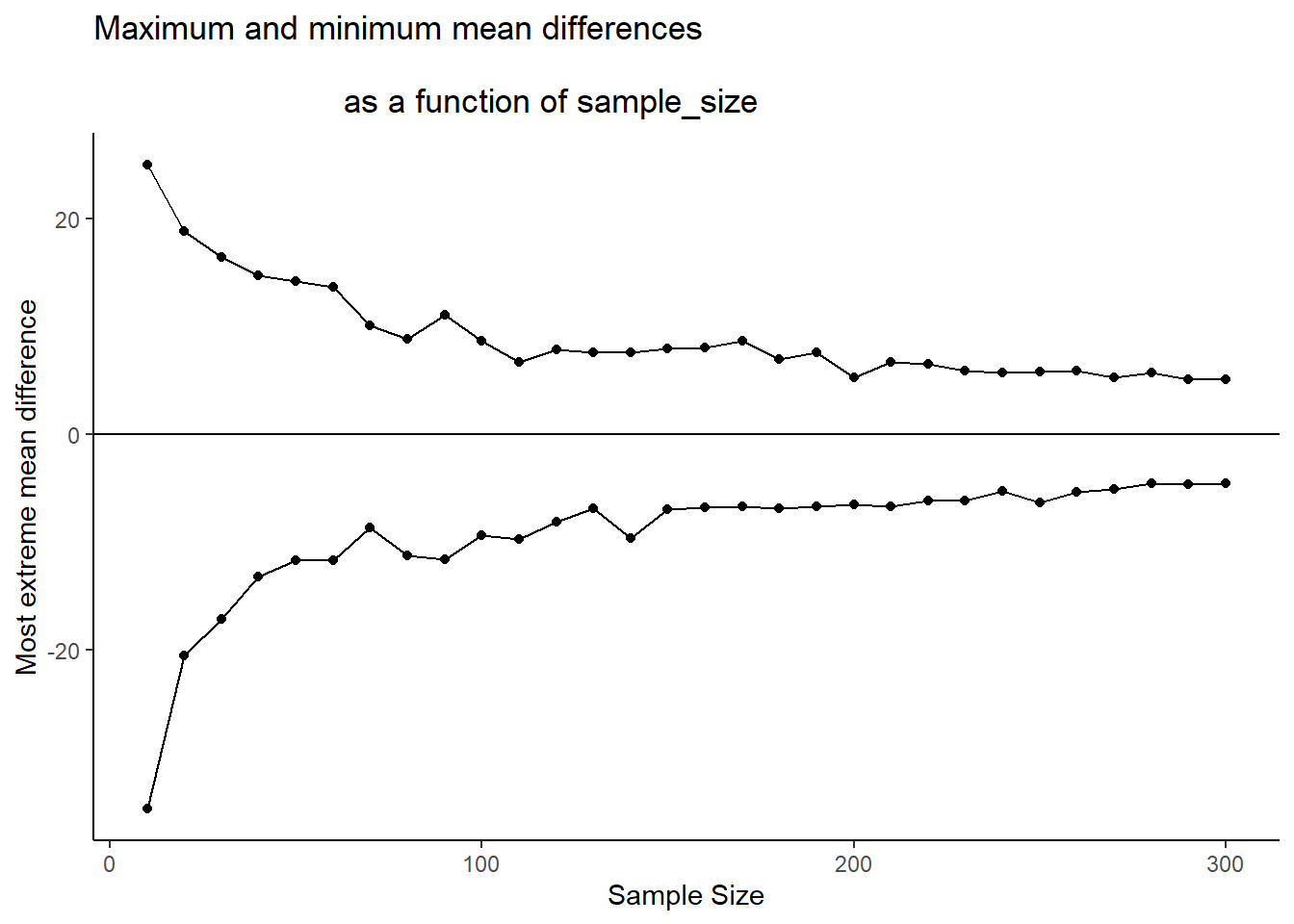
Figure 5.21: A graph of the maximum and minimum mean differences produced by chance as a function of sample-size. The range narrows as sample-size increases showing that chance alone produces a smaller range of mean differences as sample-size increases
What we have here is a reasonably precise window of sensitivity as a function of sample size. For each sample size, we can see the maximum difference that chance produced and the minimum difference. In those simulations, chance never produced bigger or smaller differences. So, each design is sensitive to any difference that is underneath the bottom line, or above the top line. It’s really that simple.
Here’s another way of putting it. Which of the sample sizes will be sensitive to a difference of +10 or -10. That is, if a difference of +10 or -10 was observed, then we could very confidently say that the difference was not due to chance, because according to these simulations, chance never produced differences that big. To help us see which ones are sensitive, let’s draw some horizontal lines at -10 and +10.
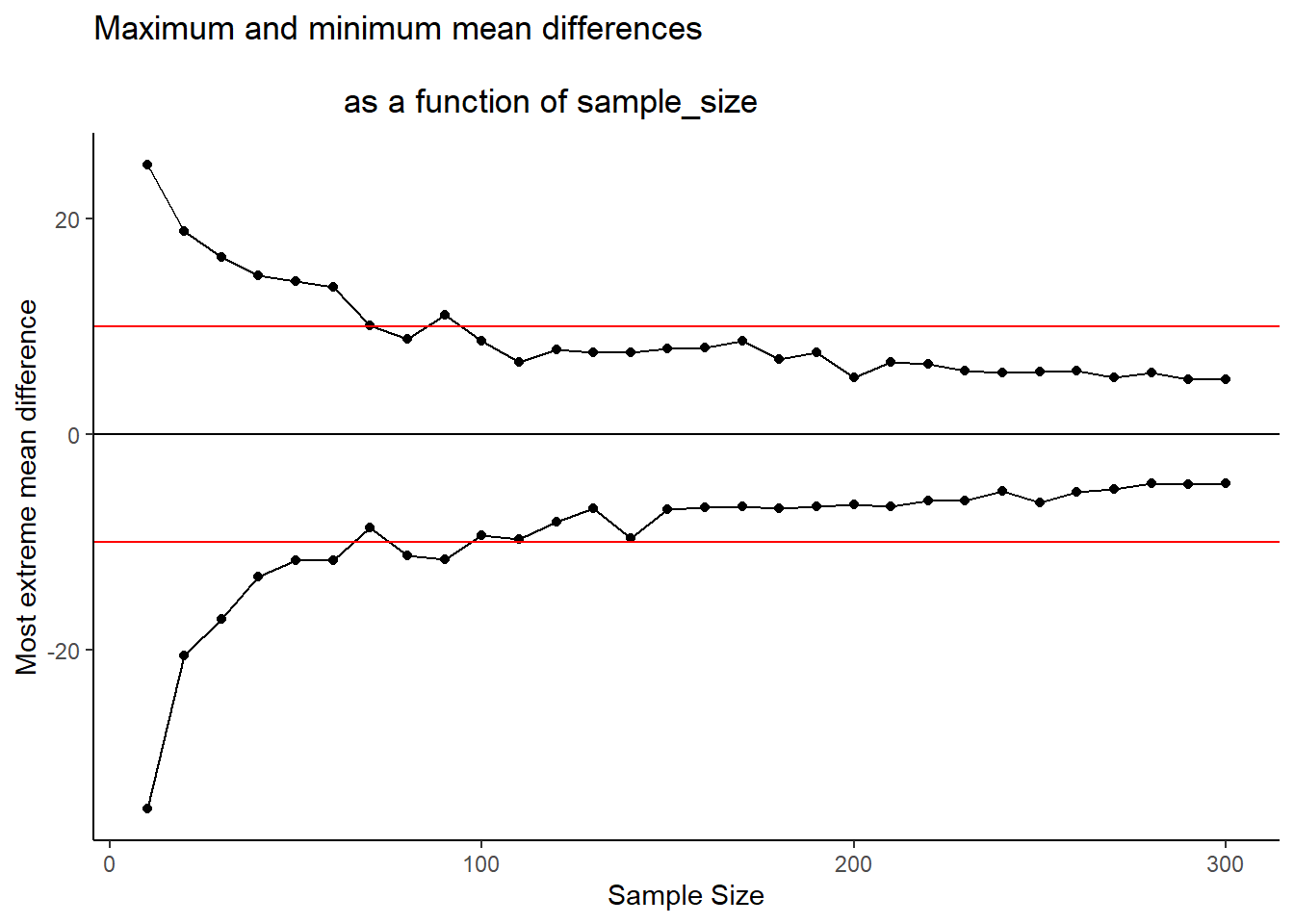
Figure 5.22: The red line represents the size of a mean difference that a researcher may be interested in detecting. All of the dots outside (above or below) the red line represent designs with small sample-sizes. When a difference of 10 occurs for these designs, we can rule out chance with confidence. The dots between the red lines represent designs with larger sample-sizes. These designs never produce differences as large as 10, so when those differences occur, we can be confident chance did not produce them
I would say all of the designs with sample size = 100 or greater are all perfectly sensitive to real differences of 10 (if they exist). We can see that all of the dots after sample size 100 are underneath the red line. So effects that are as big as the red line, or bigger will almost never occur due to chance. But, if they do occur in nature, those experiments will detect them straight away. That is sensitivity. And, designing your experiment so that you know it is sensitive to the thing you are looking for is the big idea behind power. It’s worth knowing this kind of thing before you run your experiment. Why waste your own time and run an experiment that doesn’t have a chance of detecting the thing you are looking for.
5.5.7 Summary of Crump Test
What did we learn from this so-called fake Crump test that nobody uses? Well, we learned the basics of what we’ll be doing moving forward. And, we did it all without any hard math or formulas. We sampled numbers, we computed means, we subtracted means, then we did that a lot and counted up the means and put them in a histogram. This showed us what chance do in an experiment. Then, we discussed how to make decisions around these facts. And, we showed how we can manipulate the role of chance just by changing things like sample size.
5.6 The randomization test (permutation test)
Welcome to the first official inferential statistic in this textbook. Up till now we have been building some intuitions for you. Next, we will get slightly more formal and show you how we can use random chance to tell us whether our experimental finding was likely due to chance or not. We do this with something called a randomization test. The ideas behind the randomization test are the very same ideas behind the rest of the inferential statistics that we will talk about in later chapters. And, surprise, we have already talked about all of the major ideas already. Now, we will just put the ideas together, and give them the name randomization test.
Here’s the big idea. When you run an experiment and collect some data you get to find out what happened that one time. But, because you ran the experiment only once, you don’t get to find out what could have happened. The randomization test is a way of finding out what could have happened. And, once you know that, you can compare what did happen in your experiment, with what could have happened.
5.6.1 Pretend example does chewing gum improve your grades?
Let’s say you run an experiment to find out if chewing gum causes students to get better grades on statistics exams. You randomly assign 20 students to the chewing gum condition, and 20 different students to the no-chewing gum condition. Then, you give everybody statistics tests and measure their grades. If chewing gum causes better grades, then the chewing gum group should have higher grades on average than the group who did not chew gum.
Let’s say the data looked like this:
| student | gum | no_gum |
|---|---|---|
| 1 | 87 | 68 |
| 2 | 75 | 43 |
| 3 | 89 | 45 |
| 4 | 82 | 67 |
| 5 | 90 | 84 |
| 6 | 78 | 74 |
| 7 | 88 | 83 |
| 8 | 88 | 52 |
| 9 | 89 | 59 |
| 10 | 89 | 74 |
| 11 | 74 | 66 |
| 12 | 99 | 68 |
| 13 | 82 | 61 |
| 14 | 85 | 45 |
| 15 | 88 | 83 |
| 16 | 93 | 49 |
| 17 | 92 | 41 |
| 18 | 82 | 74 |
| 19 | 88 | 49 |
| 20 | 92 | 47 |
| Sums | 1730 | 1232 |
| Means | 86.5 | 61.6 |
So, did the students chewing gum do better than the students who didn’t chew gum? Look at the mean test performance at the bottom of the table. The mean for students chewing gum was 86.5, and the mean for students who did not chew gum was 61.6. Just looking at the means, it looks like chewing gum worked!
“STOP THE PRESSES, this is silly.” We already know this is silly because we are making pretend data. But, even if this was real data, you might think, “Chewing gum won’t do anything, this difference could have been caused by chance, I mean, maybe the better students just happened to be put into the chewing group, so because of that their grades were higher, chewing gum didn’t do anything….” We agree. But, let’s take a closer look. We already know how the data come out. What we want to know is how they could have come out, what are all the possibilities?
For example, the data would have come out a bit different if we happened to have put some of the students from the gum group into the no gum group, and vice versa. Think of all the ways you could have assigned the 40 students into two groups, there are lots of ways. And, the means for each group would turn out differently depending on how the students are assigned to each group.
Practically speaking, it’s not possible to run the experiment every possible way, that would take too long. But, we can nevertheless estimate how all of those experiments might have turned out using simulation.
Here’s the idea. We will take the 40 measurements (exam scores) that we found for all the students. Then we will randomly take 20 of them and pretend they were in the gum group, and we’ll take the remaining 20 and pretend they were in the no gum group. Then we can compute the means again to find out what would have happened. We can keep doing this over and over again. Every time computing what happened in that version of the experiment.
5.6.1.1 Doing the randomization
Before we do that, let’s show how the randomization part works. We’ll use fewer numbers to make the process easier to look at. Here are the first 5 exam scores for students in both groups.
| student | gum | no_gum |
|---|---|---|
| 1 | 87 | 68 |
| 2 | 75 | 43 |
| 3 | 89 | 45 |
| 4 | 82 | 67 |
| 5 | 90 | 84 |
| Sums | 423 | 307 |
| Means | 84.6 | 61.4 |
Things could have turned out differently if some of the subjects in the gum group were switched with the subjects in the no gum group. Here’s how we can do some random switching. We will do this using R.
all_scores <- c(gum[1:5],no_gum[1:5])
randomize_scores <- sample(all_scores)
new_gum <- randomize_scores[1:5]
new_no_gum <- randomize_scores[6:10]
print(new_gum)## [1] 87 84 43 75 45print(new_no_gum)## [1] 89 68 67 82 90We have taken the first 5 numbers from the original data, and put them all into a variable called all_scores. Then we use the sample function in R to shuffle the scores. Finally, we take the first 5 scores from the shuffled numbers and put them into a new variable called new_gum. Then, we put the last five scores into the variable new_no_gum. Then we printed them, so we can see them.
If we do this a couple of times and put them in a table, we can indeed see that the means for gum and no gum would be different if the subjects were shuffled around. Check it out:
| student | gum | no_gum | gum2 | no_gum2 | gum3 | no_gum3 |
|---|---|---|---|---|---|---|
| 1 | 87 | 68 | 43 | 87 | 43 | 82 |
| 2 | 75 | 43 | 84 | 89 | 75 | 67 |
| 3 | 89 | 45 | 45 | 68 | 68 | 90 |
| 4 | 82 | 67 | 82 | 90 | 45 | 87 |
| 5 | 90 | 84 | 67 | 75 | 84 | 89 |
| Sums | 423 | 307 | 321 | 409 | 315 | 415 |
| Means | 84.6 | 61.4 | 64.2 | 81.8 | 63 | 83 |
5.6.1.2 Simulating the mean differences across the different randomizations
In our pretend experiment we found that the mean for students chewing gum was 86.5, and the mean for students who did not chew gum was 61.6. The mean difference (gum - no gum) was 24.9. This is a pretty big difference. This is what did happen. But, what could have happened? If we tried out all of the experiments where different subjects were switched around, what does the distribution of the possible mean differences look like? Let’s find out. This is what the randomization test is all about.
When we do our randomization test we will measure the mean difference in exam scores between the gum group and the no gum group. Every time we randomize we will save the mean difference.
Let’s look at a short animation of what is happening in the randomization test. Note, what you are about to see is data from a different fake experiment, but the principles are the same. We’ll return to the gum no gum experiment after the animation. The animation is showing you three important things. First, the purple dots show you the mean scores in two groups (didn’t study vs study). It looks like there is a difference, as 1 dot is lower than the other. We want to know if chance could produce a difference this big. At the beginning of the animation, the light green and red dots show the individual scores from each of 10 subjects in the design (the purple dots are the means of these original scores). Now, during the randomizations, we randomly shuffle the original scores between the groups. You can see this happening throughout the animation, as the green and red dots appear in different random combinations. The moving yellow dots show you the new means for each group after the randomization. The differences between the yellow dots show you the range of differences that chance could produce.
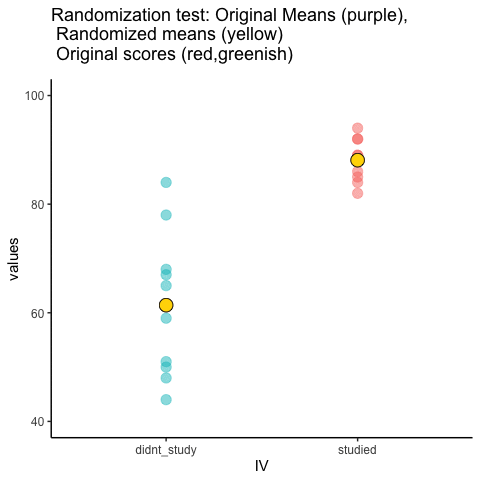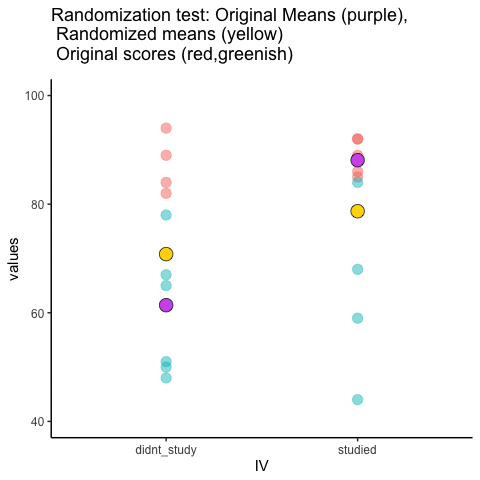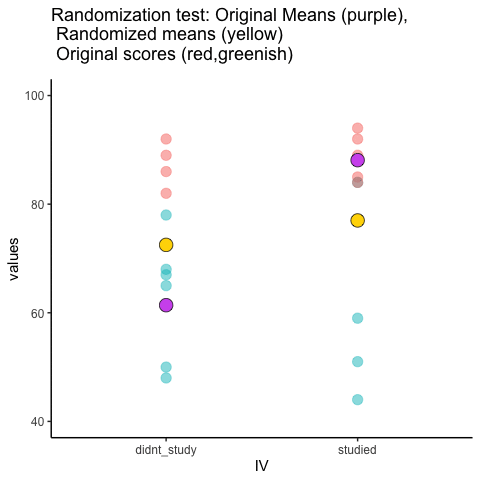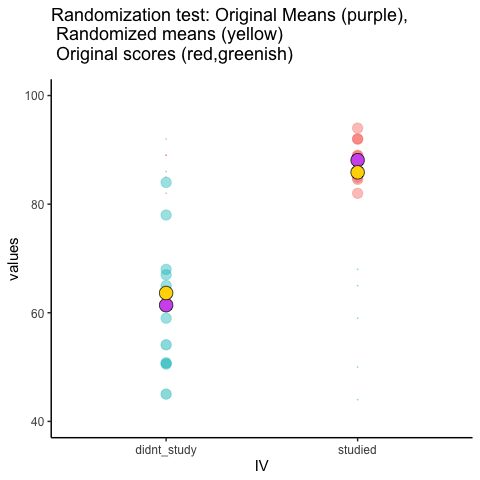
Figure 5.23: Animation of a randomization test. The purple dots represent the location of the original sample means in each condition. The yellow dots represent the means of each randomized sample. The blue and red dots show how the original scores are shuffled across each randomization.
We are engaging in some visual statistical inference. By looking at the range of motion of the yellow dots, we are watching what kind of differences chance can produce. In this animation, the purple dots, representing the original difference, are generally outside of the range of chance. The yellow dots don’t move past the purple dots, as a result chance is an unlikely explanation of the difference.
If the purple dots were inside the range of the yellow dots, then when would know that chance is capable of producing the difference we observed, and that it does so fairly often. As a result, we should not conclude the manipulation caused the difference, because it could have easily occurred by chance.
Let’s return to the gum example. After we randomize our scores many times, and computed the new means, and the mean differences, we will have loads of mean differences to look at, which we can plot in a histogram. The histogram gives a picture of what could have happened. Then, we can compare what did happen with what could have happened.
Here’s the histogram of the mean differences from the randomization test. For this simulation, we randomized the results from the original experiment 1000 times. This is what could have happened. The blue line in the figure shows us where our observed difference lies on the x-axis.
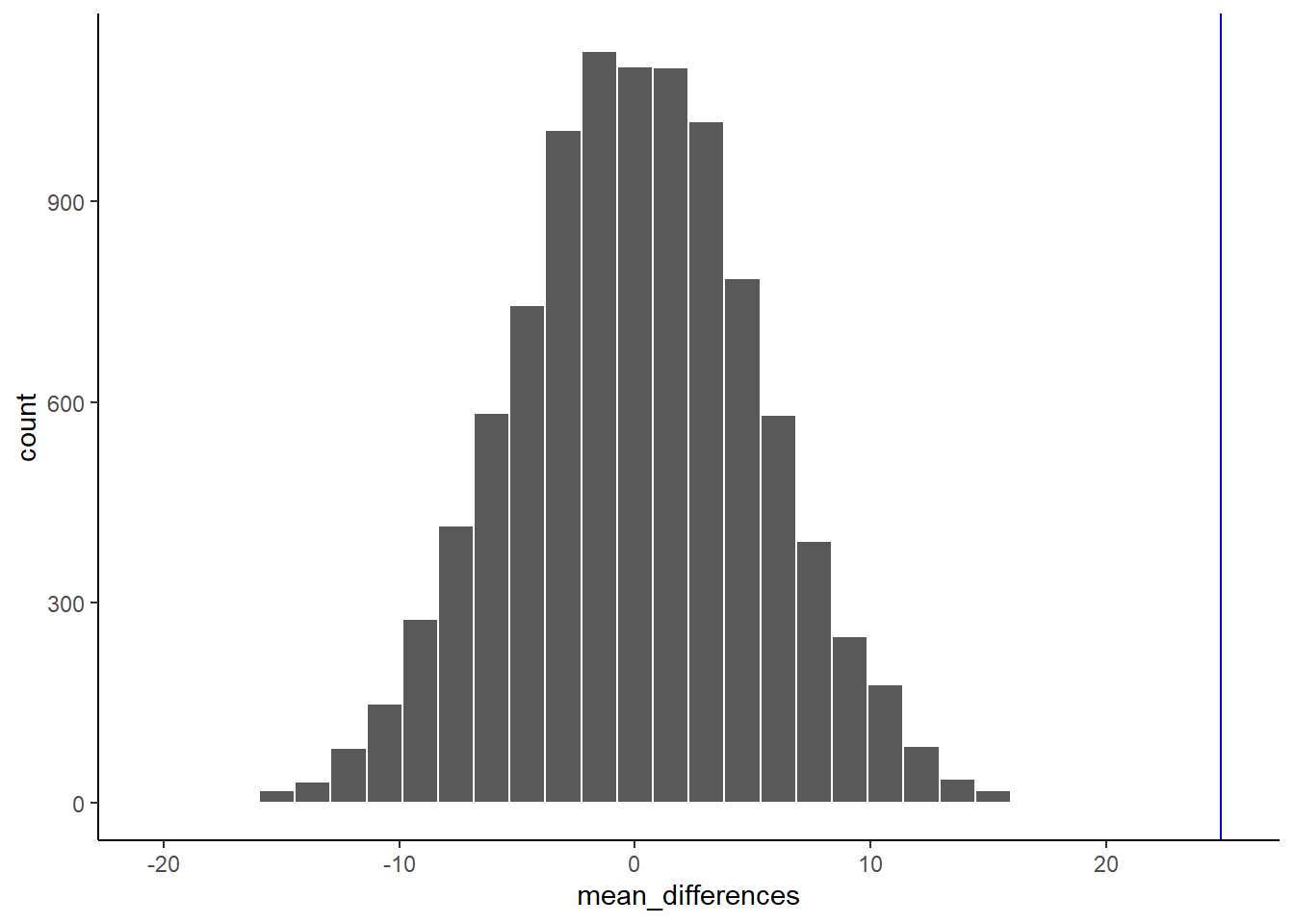
Figure 5.24: A histogram of simulated mean differences for a randomization test
What do you think? Could the difference represented by the blue line have been caused by chance? My answer is probably not. The histogram shows us the window of chance. The blue line is not inside the window. This means we can be pretty confident that the difference we observed was not due to chance.
We are looking at another window of chance. We are seeing a histogram of the kinds of mean differences that could have occurred in our experiment, if we had assigned our subjects to the gum and no gum groups differently. As you can see, the mean differences range from negative to positive. The most frequent difference is 0. Also, the distribution appears to be symmetrical about zero, which shows we had roughly same the chances of getting a positive or negative difference. Also, notice that as the differences get larger (in the positive or negative direction, they become less frequent). The blue line shows us the observed difference, this is the one we found in our fake experiment. Where is it? It’s way out to the right. It is is well outside the histogram. In other words, when we look at what could have happened, we see that what did happen doesn’t occur very often.
IMPORTANT: In this case, when we speak of what could have happened. We are talking about what could have happened by chance. When we compare what did happen to what chance could have done, we can get a better idea of whether our result was caused by chance.
OK, let’s pretend we got a much smaller mean difference when we first ran the experiment. We can draw new lines (blue and red) to represent a smaller mean we might have found.
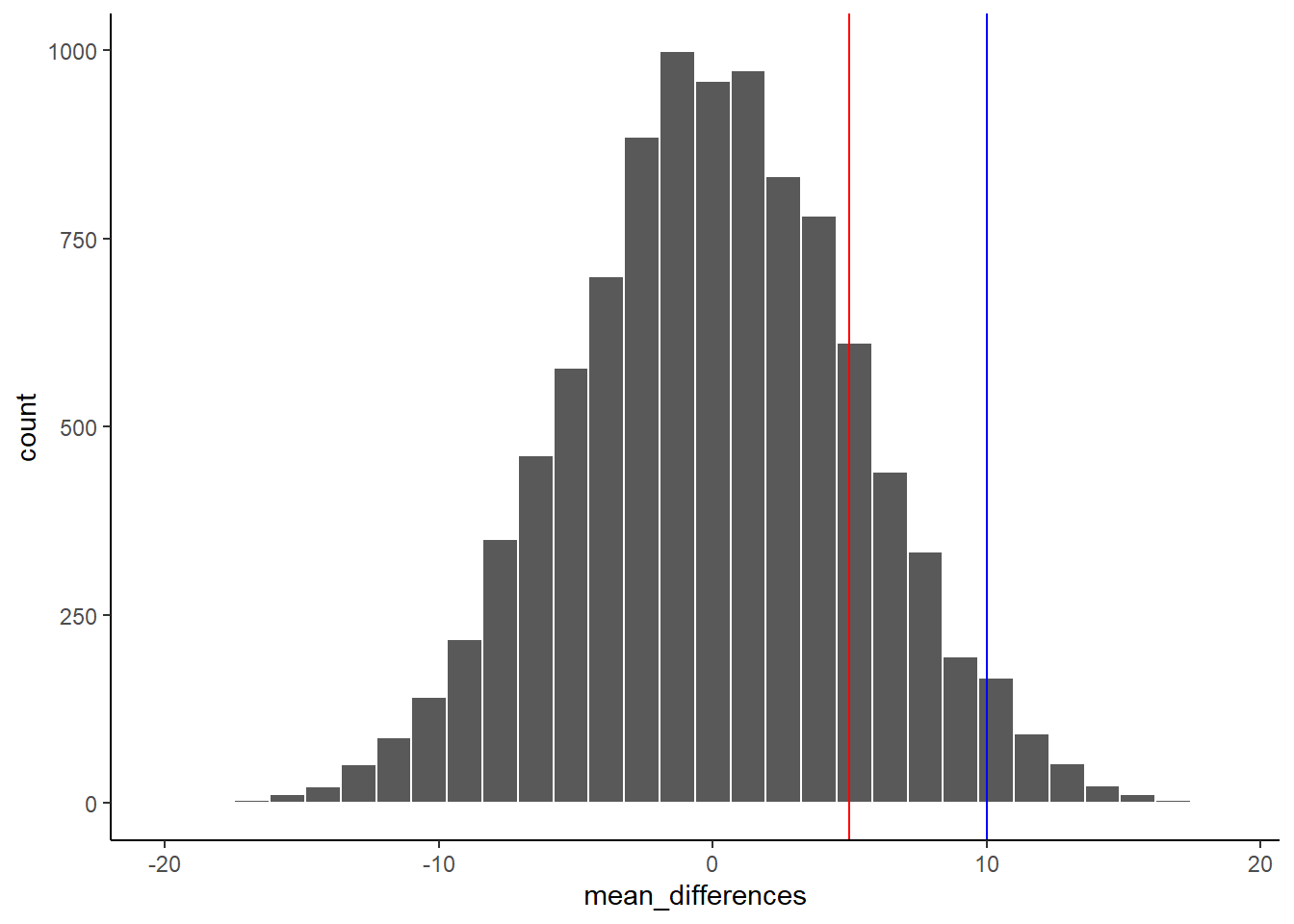
Figure 5.25: Would you expect a mean difference represented by the blue line to occur more or less often by chance compared to the mean difference represented by the red line?
Look at the blue line. If you found a mean difference of 10, would you be convinced that your difference was not caused by chance? As you can see, the blue line is inside the chance window. Notably, differences of +10 don’t very often. You might infer that your difference was not likely to be due to chance (but you might be a little bit skeptical, because it could have been). How about the red line? The red line represents a difference of +5. If you found a difference of +5 here, would you be confident that your difference was not caused by chance? I wouldn’t be. The red line is totally inside the chance window, this kind of difference happens fairly often. I’d need some more evidence to consider the claim the some independent variable actually caused the difference. I’d be much more comfortable assuming that sampling error probably caused the difference.
5.6.2 Take homes so far
Have you noticed that we haven’t used any formulas yet, but we have been able to accomplish inferential statistics. We will see some formulas as we progress, but these aren’t as the idea behind the formulas.
Inferential statistics is an attempt to solve the problem: where did my data from?. In the randomization test example, our question was: where did the differences between the means in my data come from?. We know that the differences could be produced by chance alone. We simulated what chance can due using randomization. Then we plotted what chance can do using a histogram. Then, we used to picture to help us make an inference. Did our observed difference come from the distribution, or not? When the observed difference is clearly inside the chance distribution, then we can infer that our difference could have been produced by chance. When the observed difference is not clearly inside the chance distribution, then we can infer that our difference was probably not produced by chance.
In my opinion, these pictures are very, very helpful. If one of our goals is to help ourselves summarize a bunch of complicated numbers to arrive at an inference, then the pictures do a great job. We don’t even need a summary number, we just need to look at the picture and see if the observed difference is inside or outside of the window. This is what it is all about. Creating intuitive and meaningful ways to make inferences from our data. As we move forward, the main thing that we will do is formalize our process, and talk more about “standard” inferential statistics. For example, rather than looking at a picture (which is a good thing to do), we will create some helpful numbers. For example, what if you wanted to the probability that your difference could have been produced by chance? That could be a single number, like 95%. If there was a 95% probability that chance can produce the difference you observed, you might not be very confident that something like your experimental manipulation was causing the difference. If there was only 1% probability that chance could produce your difference, then you might be more confident that chance did not produce the difference; and, you might instead be comfortable with the possibility that your experimental manipulation actually caused the difference. So, how can we arrive at those numbers? In order to get there we will introduce you to some more foundational tools for statistical inference.